Tagged: estimates
How Long Will It Take?
Estimating Software Work
Like many people who find themselves doing software development, I am sometimes asked to estimate when work will be completed. What I’m going to demonstrate is the best way I know of estimating software work completion. Next time someone asks “how long will it take?”, in the time it takes you to read this sentence, you’ll be able to answer with things like “when starting new work, there’s a 25% chance it will take us less than 3 days, 75% chance it will take us less than 37 days, and 90% chance it will take us less than 104 days” and be able to provide any other percentile you want.
First, a constraint I want in place is that people should not have to make any guesses about the nature of the work or the difficulty of the work in order to generate a reasonable estimate. This constraint is in place because in the value stream mapping sense, estimation is waste. Therefore, people not doing estimating eliminates the estimation waste.
Next, let’s go over the assumptions I’m going to make about the work. For the purpose of estimation:
Work is some problem to be solved. When the problem is solved, the work is completed.
Work is in the domain of software development. This is where my experience lies, this is the domain I’ve been asked to estimate.
The nature of the work does not matter. It can be a typo in information being displayed, or it can be a customer-facing availability outage for unknown reasons.
We do not know the probability distribution of the work. This last assumption will take some explaining.
Imagine that you have a record of the work you’ve completed over some period of time in the past, for example over the past two years you’ve completed 150 work items. For each work item (a solved problem), you have a start date and an end date. These give you a duration of the work, or how long a work item took to complete. So, in our example, you would have a list of 150 durations. If you were to create a histogram of work duration, you would see a duration distribution of the work. The assumption that “we do not know the probability distribution of the work” means that we do not know what duration distribution of the work will look like ahead of time. We might be able to determine the distribution only in hindsight. But, estimation does not happen in hindsight, therefore, at the time we have to make estimates we do not know the probability distribution of the work.
In case you think that work is normally distributed (as in, the typical bell curve that is easy to do statistics with), here is a histogram of 150 actual durations:
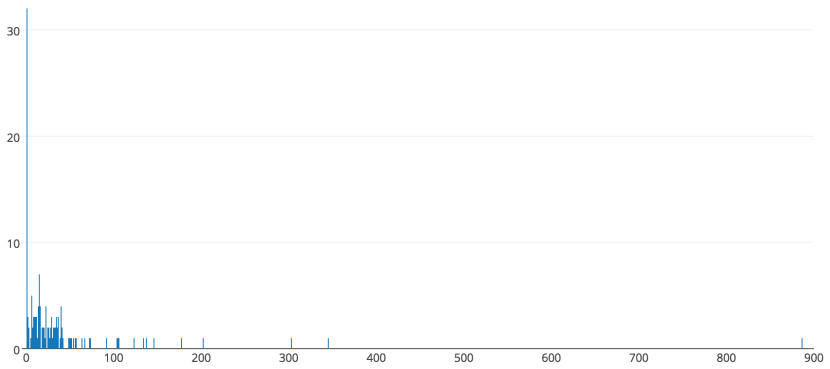
Created using: https://plot.ly/create/histogram/
Now, 150 data points does not a large sample make. So, we’ll need to make another assumption.
Previously observed work durations are representative of the probability distribution of the work. That is, we assume that our past data comes from the same probability distribution of work that our future data will come from1.
If our past data is representative of the probability distribution of future data, we can go through a process of bootstrapping, and generate a much larger data set than 150. We do this by random sampling with replacement of our 150 point data set, to generate, say 1,000 point data set. Basically, we randomly pick one of the 150 points, add it to our 1,000 point data set (which now has one point in it), and put it back into the 150 point data set. We then randomly pick another one of the 150 points, add it to our 1,000 point data set (which now has two points in it), and put it back into the 150 point data set. We repeat until we sampled 1,000 points from the 150 points. What this gives us is an estimate of the “true” probability distribution of the work, given our previous assumptions.
With the resultant 1,000 points, we now sort them from shortest to longest duration. The 90th percentile answer for “how long will it take?” is the 90th percentile of the sorted 1,000 points, in our example, it turns out to be 103.73125 days, or under 104 days. That’s it. If you automate this, you’ll be able to rapidly provide any estimate of work completion to whatever percentile you’d like2.
One more thing…
There is an interesting, and I believe important, question to consider aside from “how long will it take?”. That is, “how long will it take to finish work you already have in progress?”. The answer is surprising (at least it was to me the first time I saw what happens). Let’s go through an example.
In this example, I will just use ten data points as our entire sample to illustrate what happens. Here they are, duration of completed work in days:
0.5, 0.5, 0.75, 1.0, 1.5, 3, 5, 7, 10, 21.5
Given the above historical data, consider now that you are about to start the next work item. In other words, all we know about the work item is that we haven’t started it yet. Therefore, we use all of our ten example data points to bootstrap a larger data set with 1,000 data points, and once we have that, we sort it, and then pick, for example, the 90th percentile. Nothing different from what we’ve already demonstrated.
However, now imagine that it is two days later, and we are still working on our work item. How would we answer the question of how long it will take us to finish? There is a key difference after two days of work, and that is that we have learned that our work item takes at least two days of work. When, after two days of work, we ask the question how long it will take us to finish, what we are really asking is “how long will it take to finish a work item that takes at least two days to finish?”. To answer this question, it makes no sense to use any data points that are less than two days in duration. Data points less than two days in duration clearly do not represent the type of work we are attempting to estimate completion of. If the work was of the type that takes less than two days to do, it would be finished already. So, without data points of less than two days, our data points to bootstrap from are now:
3, 5, 7, 10, 21.5
If you bootstrap from these data points, something interesting happens, and that is, that the 90th percentile will now very likely be further in the future than the estimate you gave when you asked the question two days prior. So, on day 0, when you haven’t started work, you used all data points, and the 90th percentile could end up being 10 days to finish. On day 2, when you worked for two days, using the newly learned information, we update our starting data set, and the 90th percentile could end up being 21.5 days to finish.
In fact, if you’re working on a work item, and every day you ask “how long will it take to finish?” the answer tends to be further and further in the future3.
Here is an example of the 90th percentile estimate for work item duration if we ask the question for the first thirty days, and the work item is not finished:

Created using: https://plot.ly/create
Wait, what?!
What I presented here is, I think, a reasonable methodology for estimating work. It works at a level of solving problems, which is what “the business” usually cares about. It makes reasonable assumptions, it gives estimates as percentiles, which is better than a single estimate because we can adjust for our individual risk tolerance. Also, this method generates estimates without involvement of any human (once it is automated).
Then again, because this method is automated, it allows us to ask the question “how long will it take?” as often as we like. What we learn, is that every time we ask, the answer will be further in the future, and we will be more confident of the answer.
The best time to know when something is done, is when it is finished. But if you insist on asking, you might not like the answer.
Endnotes
1 More precisely, I am assuming that the past data comes from the same generator type that our future data will come from. The distinction, while interesting, isn’t important to the overall effort, so I won’t cover it further in this post.
2 To be even more… statistically valid (maybe?), you could regenerate your 1,000 point data set many times and take the average of the percentile you’re interested in across each generation. Then you can say you’re using a Monte Carlo method to derive your estimates.
3 I find this is a rather fascinating manifestation of the Lindy Effect.
