Excession
Black Swans and Turkey Problems

The concept of the Black Swan was popularized by Nassim Nicholas Taleb in his 2007 book by the same name. Over many introductions of this concept to friends and colleagues, I observed that it is an easy concept to describe but a difficult one to grasp.
Unknown Unknown
Perhaps you’ve heard the following framing before. There are things we know we know: known knowns. There are things we know we don’t know: known unknowns. Then, there are things we don’t know, we don’t know: unknown unknowns. A Black Swan is an unknown unknown, an event that we did not see coming and had no way of knowing was coming. A Black Swan surprises us in a way we didn’t know we could be surprised. A Black Swan happens because we didn’t know what we didn’t know. That’s the simple description. It is straightforward, but its implications are not.
You cannot anticipate a Black Swan.
Again, you cannot anticipate a Black Swan.
If you think you can, then it is not a Black Swan you are anticipating. This is not any easy concept to wrap one’s head around. Consider that if you could anticipate it, then that means you know something or that you know that you don’t know something. But, that is either known known or known unknown. A Black Swan is an unknown unknown.
It gets worse.
A Black Swan will happen when you are maximally certain that it will not.
Fundamental Surprise
In his book, Taleb describes the Turkey Problem. Imagine a turkey scientist. As a turkey scientist, the turkey decides to better understand farmer-turkey relations. As part of the study, it attempts to predict farmer behavior and makes the following observation: “Day 1, farmer feeds me.” The turkey continues to make observations day by day: “Day 2, farmer feeds me”, “Day 3, farmer feeds me”, … and so on for 111 days. On day 111, what is the turkey’s model for farmer behavior? It probably looks something like this:
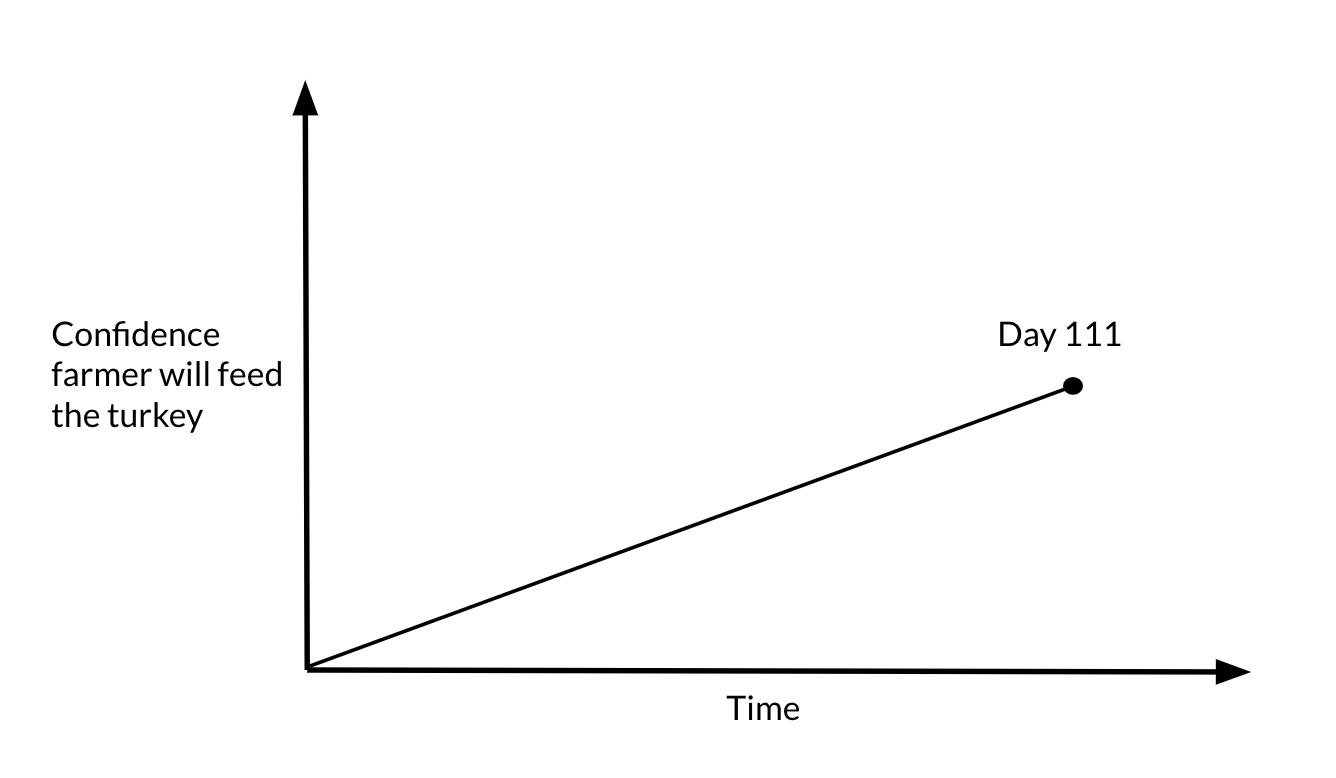
Unbeknownst to the turkey, Day 111 is the day before the U.S. Thanksgiving holiday, and the farmer instead of feeding the turkey slaughters it.
You cannot anticipate a Black Swan.
A Black Swan will happen when you are maximally certain that it will not.
Day 111 is the day when the turkey scientist has highest confidence that it will be fed. Everything in its entire existence taught it that food was coming on Day 111.
Outside Context Problem
The usual example given to illustrate an Outside Context Problem was imagining you were a tribe on a largish, fertile island; you’d tamed the land, invented the wheel or writing or whatever, the neighbors were cooperative or enslaved but at any rate peaceful and you were busy raising temples to yourself with all the excess productive capacity you had, you were in a position of near-absolute power and control which your hallowed ancestors could hardly have dreamed of and the whole situation was just running along nicely like a canoe on wet grass… when suddenly this bristling lump of iron appears sailless and trailing steam in the bay and these guys carrying long funny-looking sticks come ashore and announce you’ve just been discovered, you’re all subjects of the Emperor now, he’s keen on presents called tax and these bright-eyed holy men would like a word with your priests.
Banks, Iain M (1996). “Excession”.
The Outside Context Problem, the Turkey Problem, Fundamental Surprise, Unknown Unknown, the Black Swan, all are attempting to pinpoint something very straightforward to state but very difficult to accept.
In a complex world, you cannot predict the future.
I will leave you with a final reflection. Consider the events in your past that changed the course of your life. How many of them did you plan and predict? How many just happened to you?
What Do You Think?
Do you feel the essence of what a Black Swan is? On the other hand, do you think you can predict the future? Perhaps you know how to reduce the frequency of Black Swans? Let me know in the comments.
Next Up
I will write about How Complex Systems Fail.