Category: Uncategorized
Excession
Black Swans and Turkey Problems

The concept of the Black Swan was popularized by Nassim Nicholas Taleb in his 2007 book by the same name. Over many introductions of this concept to friends and colleagues, I observed that it is an easy concept to describe but a difficult one to grasp.
Unknown Unknown
Perhaps you’ve heard the following framing before. There are things we know we know: known knowns. There are things we know we don’t know: known unknowns. Then, there are things we don’t know, we don’t know: unknown unknowns. A Black Swan is an unknown unknown, an event that we did not see coming and had no way of knowing was coming. A Black Swan surprises us in a way we didn’t know we could be surprised. A Black Swan happens because we didn’t know what we didn’t know. That’s the simple description. It is straightforward, but its implications are not.
You cannot anticipate a Black Swan.
Again, you cannot anticipate a Black Swan.
If you think you can, then it is not a Black Swan you are anticipating. This is not any easy concept to wrap one’s head around. Consider that if you could anticipate it, then that means you know something or that you know that you don’t know something. But, that is either known known or known unknown. A Black Swan is an unknown unknown.
It gets worse.
A Black Swan will happen when you are maximally certain that it will not.
Fundamental Surprise
In his book, Taleb describes the Turkey Problem. Imagine a turkey scientist. As a turkey scientist, the turkey decides to better understand farmer-turkey relations. As part of the study, it attempts to predict farmer behavior and makes the following observation: “Day 1, farmer feeds me.” The turkey continues to make observations day by day: “Day 2, farmer feeds me”, “Day 3, farmer feeds me”, … and so on for 111 days. On day 111, what is the turkey’s model for farmer behavior? It probably looks something like this:
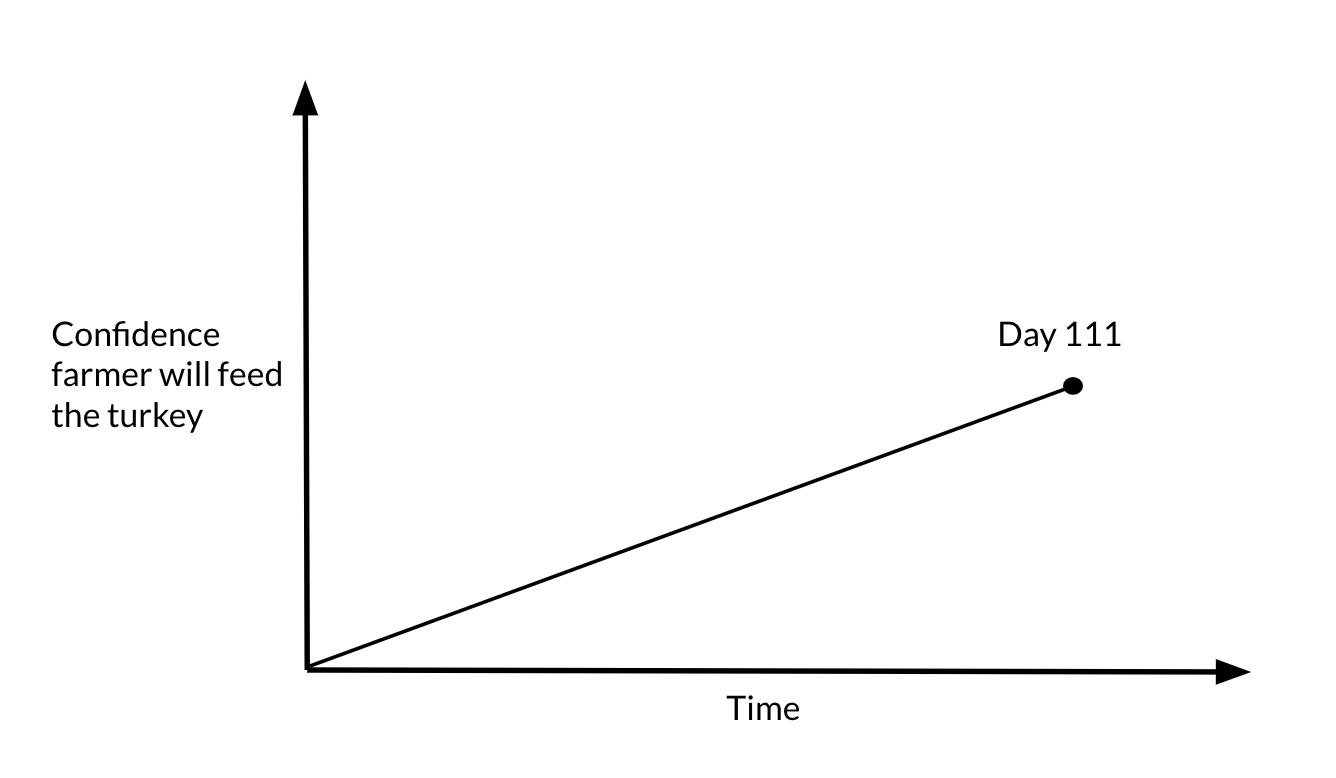
Unbeknownst to the turkey, Day 111 is the day before the U.S. Thanksgiving holiday, and the farmer instead of feeding the turkey slaughters it.
You cannot anticipate a Black Swan.
A Black Swan will happen when you are maximally certain that it will not.
Day 111 is the day when the turkey scientist has highest confidence that it will be fed. Everything in its entire existence taught it that food was coming on Day 111.
Outside Context Problem
The usual example given to illustrate an Outside Context Problem was imagining you were a tribe on a largish, fertile island; you’d tamed the land, invented the wheel or writing or whatever, the neighbors were cooperative or enslaved but at any rate peaceful and you were busy raising temples to yourself with all the excess productive capacity you had, you were in a position of near-absolute power and control which your hallowed ancestors could hardly have dreamed of and the whole situation was just running along nicely like a canoe on wet grass… when suddenly this bristling lump of iron appears sailless and trailing steam in the bay and these guys carrying long funny-looking sticks come ashore and announce you’ve just been discovered, you’re all subjects of the Emperor now, he’s keen on presents called tax and these bright-eyed holy men would like a word with your priests.
Banks, Iain M (1996). “Excession”.
The Outside Context Problem, the Turkey Problem, Fundamental Surprise, Unknown Unknown, the Black Swan, all are attempting to pinpoint something very straightforward to state but very difficult to accept.
In a complex world, you cannot predict the future.
I will leave you with a final reflection. Consider the events in your past that changed the course of your life. How many of them did you plan and predict? How many just happened to you?
What Do You Think?
Do you feel the essence of what a Black Swan is? On the other hand, do you think you can predict the future? Perhaps you know how to reduce the frequency of Black Swans? Let me know in the comments.
Next Up
I will write about How Complex Systems Fail.
Aporia
What to Do When in Doubt

In a previous post on complexity, I highlighted Liz Keogh’s shortcut for complexity estimation in order to quickly figure out the complexity of the system. In this post I will share Dave Snowden’s Cynefin approach for dealing with aporia and figuring out what to do when in doubt about what to do.1
An expression of doubt
So far, in my introduction of Dave Snowden’s Cynefin framework, I focused on the four domains: Clear, Complicated, Complex, and Chaotic. However, there are additional aspects of the framework I haven’t highlighted until now. For example, in the space in the center, between the domains, we see “AC”, which is the Confused domain.

The distinction between A and C in the Confused domain is intended to convey distinction between being active and being passive. In being passive, one remains Confused, and tends to drift toward their favorite action heuristic: Clear, Complicated, Complex, or Chaotic, whether it is appropriate or not. The danger being accidentally slipping into Chaos. In being active, one expresses Aporia (the expression of doubt) where one is actively confused and is attempting to unconfuse themselves.
“The instance of a decision is a madness”2
Snowden articulates six pathways out of Aporia from low to high risk, suggesting an order of elimination in how to proceed out of doubt. I paraphrase below.3

- If expert advice is questionable, shift provisionally into Complicated and set up a rapid debate between experts and people with different backgrounds to see whether expert analysis will be sufficient.
- Shift into Complex, identify multiple coherent contradictory hypotheses with champions, and conduct safe-to-fail experiments to discover more about the context.
- Shift into Complicated if there is a clear and obvious body of knowledge that you’ve been ignoring or didn’t know about so far. Perhaps the experts were right and it’s time to listen to them.
- If you’re concerned that you may not be seeing something essential, shift into the Chaotic-Complex liminal zone and identify multiple perspectives, especially minority perspectives. Outliers are very valuable as they provide diverse points of view and may offer hypotheses to be tested. Diversity here is key.
- If you can no longer tolerate Aporetic state, you may choose to enter into the Chaotic domain where you begin crisis management, exert control and take direct action to attempt to resolve the situation without necessarily having control over what way it resolves.
- Lastly, the most risky approach is to shift into Clear and assume that you need to apply standard processes and procedures harder.
Linguistic, Aesthetic, Physical
Now, it may seem that being in doubt is not desirable. This is not always the case. Snowden points out that we may want to enter Aporia deliberately if we begin to observe our approaches are failing and perhaps we need to reconsider our assumptions. To deliberately induce Aporia, consider linguistic, aesthetic, and physical techniques.
Linguistic approach is to use language: neologisms, foreign words, paradox, metaphor, counterfactuals, poetry, or quotations.4
Aesthetic approach is to use art: cartoons, illustrations, fine art, photographs, satire, improv, music, etc.5
Physical approach is to use the body: physical exercise, practice of craft, fasting, and other embodied approaches.6 I can personally vouch for this approach having ridden 2783.6 miles of the Continental Divide on a bicycle. This may be an extreme example, but it took me a few months to care about my professional career again after I got back.
What Do You Think?
Confusion is not something I naturally seek out. Do you deliberately enter the state of Aporia? What do you get out of it? Let me know in the comments.
Next Up
I will set aside the Cynefin framework and continue to explore complexity, this time through the framing of Black Swans and Turkey Problems: Excession.
1 Snowden, David J (2020). “Cynefin St David’s Day (5 of 5)”. https://www.cognitive-edge.com/cynefin-st-davids-day-5-of-5/. Accessed on 17 Mar 2021.
2 Derrida quoting Kierkegaard in Derrida’s “Dialanguages” in “Points: Interviews 1974–1994”(Stanford, Stanford University Press, 1995, 147–8.).
3 See Snowden, David J (2020). “Cynefin St David’s Day (5 of 5)”. https://www.cognitive-edge.com/cynefin-st-davids-day-5-of-5/. for more precise descriptions.
4 Snowden, David J (2021). “Linguistic aporia”. https://www.cognitive-edge.com/linguistic-aporia/. Accessed on 17 Mar 2021.
5 Snowden, David J (2021). “Aesthetic aporia”. https://www.cognitive-edge.com/aesthetic-aporia/. Accessed on 17 Mar 2021.
6 Snowden, David J (2021). “Physical aporia”. https://www.cognitive-edge.com/physical-aporia/. Accessed on 17 Mar 2021.
Economy of Thought
Complexity is Expensive

This is the third post on defining complexity in the onboarding series. I highlighted before that, in a complex system, the relationship between cause and effect is knowable only in hindsight. Additionally, our constraints will change on the timescale under consideration. A sense-making heuristic is to probe-sense-respond using exaptive practices. In this post, I’ll highlight that this is expensive.
Finite Capacity
Our ability to think is, on the one hand, vast. On the other hand, we can only think so much and think only so fast. Ultimately, we have a finite amount of time to think. When dealing with finite resources, we can frame things in terms of an economy. There are two complementary definitions that I have in mind:
“efficient and concise use of nonmaterial resources (such as effort, language, or motion)”
“the arrangement or mode of operation of something”
“Economy.” Merriam-Webster.com Dictionary, Merriam-Webster, https://www.merriam-webster.com/dictionary/economy. Accessed on 10 Mar 2021.
When applied to thinking, we can imagine an Economy of Thought, that is, the arrangement of our thinking in order to make efficient and concise use of the finite amount of time available.
The Expense
From the frame of Economy of Thought, it turns out that thinking in the Complex Cynefin domain is the most expensive.
In the Ordered domains (Clear and Complicated), constraints do not change. I can come to know something and then I can rely on that knowledge not changing. “Things fall” is an unchanging knowledge. Logging into my email account is unchanging knowledge (on the relevant timescale). Traffic laws guiding me how to drive a car is unchanging knowledge (on the relevant timescale). Through the framing of Economy of Thought, I can learn Clear and Complicated things once, and rely on them from then on.
Chaotic domain is demanding, but it is transient and tends to resolve into other domains.
In the Complex domain, well… here be dragons. Constraints change, and they can change due to our actions. I can come to know something, only for that knowledge to change once I look away (imagine playing a visually demanding sport with your eyes closed). In order to remain relevant in the Complex domain, I need to be continuously engaged. I need to always look for the latest changes to update my knowledge. I have to be in a constant feedback loop with the domain to keep up to date knowledge. I need to keep up to date knowledge because the knowledge changes when I don’t look. This is expensive.
A Choice
Considering the world through the frame of Cynefin, I see the world in the Complex domain. The world is complex, therefore I must constantly probe-sense-respond to make sense of the world. However, the frame of Economy of Thought offers me a choice. While I can choose to expend all of me on all of the complexity of the world, I can also choose not to do that. I can approximate parts of the world as Complicated or Clear. In fact, all of us do this constantly. Our brains evolved to predict the patterns in time and space that allow for these Complicated and Clear shortcuts. Having a Cynefin frame of reference highlights that I can make a deliberate choice in how to engage with the world. I can choose to engage in complexity and maintain a tight feedback loop where required. At the same time I can summarize other complexity and treat it as Clear or Complicated if I don’t think constraints will change. I can be economical. I can arrange my thinking to make efficient and concise use of the finite amount of time available.
What Do You Think?
What’s your usual approach towards the world? Is it Clear, Complicated, Complex? Let me know in the comments.
Next Up
Next, I’ll write about how to decide when to take a Clear or Complicated shortcut: Aporia.
Cynefin Complexity
The Cynefin Framework

Last time in the onboarding series I wrote about complexity through the frame of relationship between cause and effect in the world. Today, I want to introduce Dave Snowden’s Cynefin framework1 which underpins what I mean by complexity.
Ordered Systems
So far, I defined an Ordered System as a system where a relationship between cause and effect can be determined. The relationship could be clear or discovered through analysis. When the relationship is clear, that is a Clear System.

For a Clear System, the sense-making heuristic is sense-categorize-respond. We sense the situation, we categorize it (because cause and effect are clear), and we respond using the Best practice available for the category we selected. The constraints are Fixed, do not change, and will probably never change on the timescale under consideration (whether we act or not).
When the relationship between cause and effect can be discovered through analysis, that is a Complicated System.

For a Complicated System, the sense-making heuristic is sense-analyze-respond. We sense the situation, we analyze it (because cause and effect can be determined through analysis), and we respond using one of the Good practices available.2 The constraints are Governing constraints, “…[they] provide limits to what can be done. In terms of our policies and processes, these are hard-and-fast rules. They are context-free, which means they apply to everything, regardless of context.”3 Because we enforce the constraints, the constraints do not change (similarly to Fixed constraints), and will probably never change on the timescale under consideration (whether we act or not).
Chaotic Systems
When the relationship between cause and effect cannot be determined, that is a Chaotic System.

For a Chaotic System, the heuristic is to act-sense-respond. We act to establish order, we sense where stability lies, and we respond using Novel methods attempting to turn chaos into complexity.4 There are no constraints. “Chaos is caused by a lack of constraints; meeting constraints will cause it to dissipate. Think of fire burning until it runs out of fuel or oxygen. This is what makes Chaos transient and short-lived; it will rapidly grow until it meets constraints, at which point the situation resolves (but not necessarily in your favour).”5
Complex Systems
When the relationship between cause and effect can only be determined in hindsight, that is a Complex System.

For a Complex System, the heuristic for sense-making is probe-sense-respond. We probe via multiple parallel and independent safe-to-fail experiments. We sense whether our probes are working, and we respond using Exaptive6 practices. If a probe is working, we reinforce it. If a probe is failing, we should dampen it. We should not conduct the probes in the first place unless we’ve identified amplification/reinforcement and dampening strategies ahead of time. The constraints are Enabling in the sense that they constrain what probes we can conduct (as opposed to any probe imaginable if there were no constraints). The constraints will change on the timescale under consideration due to our own actions (probes) and external factors.
A Cheat Sheet
Liz Keogh has a very useful shortcut for estimating complexity to get you started7:
5. Nobody has ever done it before.
4. Someone outside the organization has done it before (probably a competitor)
3. Someone in the company has done it before.
2. Someone in the team has done it before.
1. We all know how to do it.
What Do You Think?
This was quite a lot of dense exposition. If you feel something could use more clarification, let me know in the comments.
Next Up
I’ll continue sharpening the definition of complex through the framing I call the Economy of Thought.
1 https://en.wikipedia.org/wiki/Cynefin_framework. Accessed on 9 Mar 2021.
2 It is worth noting that given you have the appropriate expertise, there are likely multiple good approaches to take. Pick one.
3 Keogh, Liz (2019). “Constraints and Cynefin”. https://lizkeogh.com/2019/12/09/constraints-and-cynefin/. Accessed on 9 Mar 2021.
4 Snowden, David J.; Boone, Mary E. (2007). “A Leader’s Framework for Decision Making”. https://hbr.org/2007/11/a-leaders-framework-for-decision-making. Accessed on 9 Mar 2021.
5 Keogh (2019).
6 Exaptive in the sense that we are using our existing capabilities and exapting them for novel purposes that they were perhaps not originally intended for. Think of using a piece of paper to keep a chair from rocking back and forth.
7 Keogh, Liz (2013). “Estimating Complexity”. https://lizkeogh.com/2013/07/21/estimating-complexity/. Accessed on 10 Mar 2021. Accompanying illustration is based on one of Keogh’s presentations.
Wardley Maps and a Thousand Brains
Why Maps Are Effective Tools

I made a claim on Twitter recently that Jeff Hawkins’ new book: “A Thousand Brains: A New Theory of Intelligence”, explains why a map is an effective tool for the human brain.
Reference Frames
The key insight of the Thousand Brains theory is that the primary purpose of the neocortex is to process reference frames.
Each column in the neocortex—whether it represents visual input, tactile input, auditory input, language, or high-level thought—must have neurons that represent reference frames and locations.
Up to that point, most neuroscientists, including me, thought that the neocortex primarily processed sensory input. What I realized that day is that we need to think of the neocortex as primarily processing reference frames. Most of the circuitry is there to create reference frames and track locations. Sensory input is of course essential. As I will explain in coming chapters, the brain builds models of the world by associating sensory input with locations in reference frames.
Hawkins, Jeff. A Thousand Brains (p. 50). Basic Books. Kindle Edition.
Recall that a reference frame is like the grid of a map.
Hawkins, (p. 59).
This has implications for what thinking actually is. All knowledge is stored in reference frames and thinking is a form of moving.
The hypothesis I explore in this chapter is that the brain arranges all knowledge using reference frames, and that thinking is a form of moving. Thinking occurs when we activate successive locations in reference frames.
Hawkins, (p. 71)
If everything we know is stored in reference frames, then to recall stored knowledge we have to activate the appropriate locations in the appropriate reference frames. Thinking occurs when the neurons invoke location after location in a reference frame, bringing to mind what was stored in each location. The succession of thoughts that we experience when thinking is analogous to the (…) succession of things we see when we walk about a town.
Hawkins, (p. 73)
The process of thinking is described as movement on a map!
Maps
Simon Wardley articulates exactly what is needed for an abstract map. He captures the map’s essence.
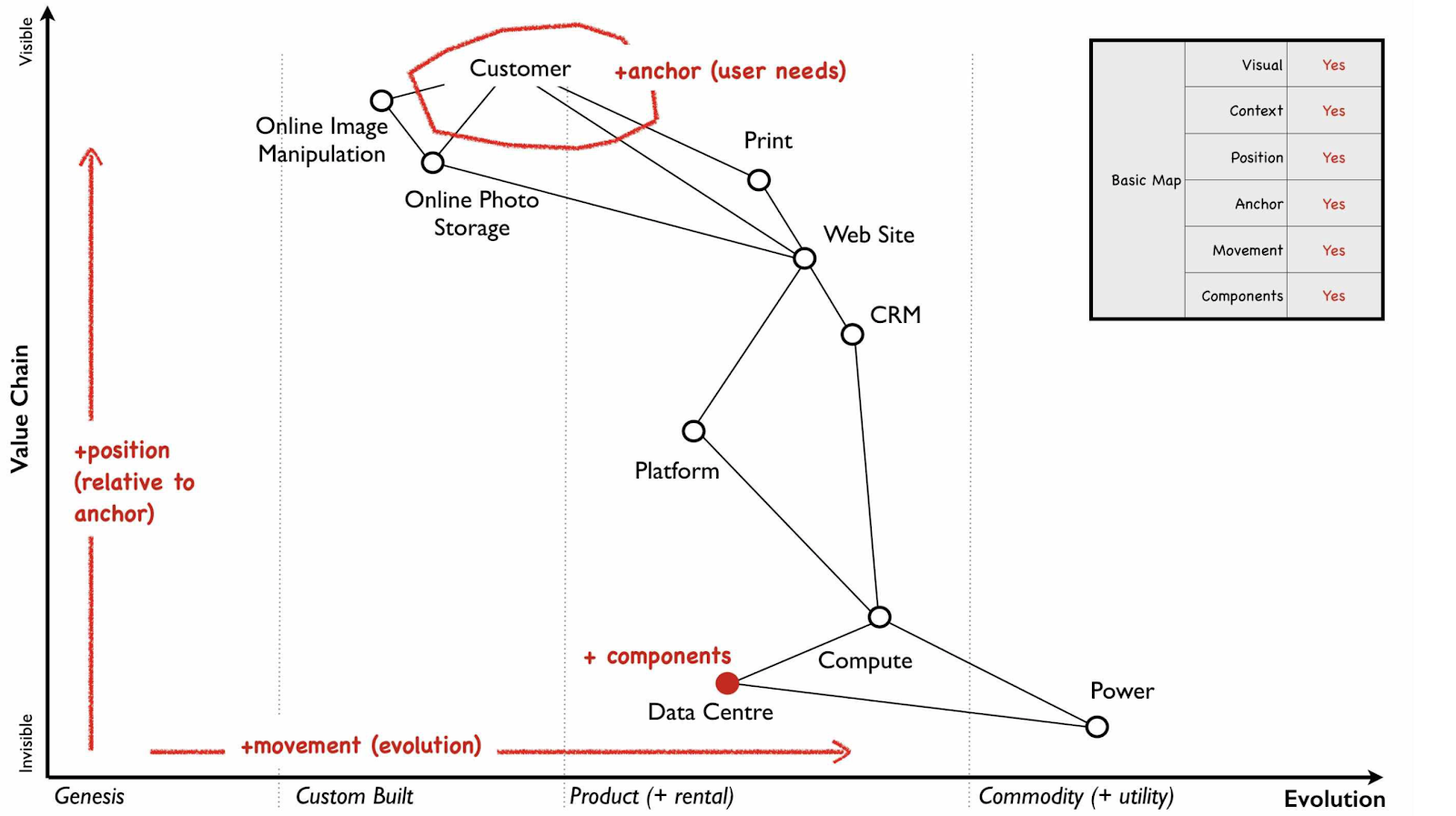
Maps are visual and context specific. The position of components has meaning based on the anchor. There is movement.1
To be an expert in any domain requires having a good reference frame, a good map.
Hawkins, (p. 87)
I believe that the reason why Wardley Maps are effective is that they are a reference frame for business. They are effective because they are in a form which allows our brains to think most naturally. They also happen to be a useful reference frame.
Beyond Wardley Maps
The reason for my excited tweet was a realization that Simon Wardley’s criteria of what makes something a map can be translated into a criteria of what makes something a good tool for our human brain.
We have a clear set of constraints for creating really useful tools for the mind!
What Do You Think?
Did you already know how to make useful mind tools, what was your approach? Let me know in the comments.
1 Simon Wardley. Chapter 2: Finding a path. https://medium.com/wardleymaps/finding-a-path-cdb1249078c0. Accessed on 5 Mar 2021.
A Complex World
In Hindsight

As I shared before, my primary principle is: We want to thrive in a complex world. In this post I will elaborate on what I mean by complex.
How to Organize a Children’s Party
First, a three minute introduction to complexity by Dave Snowden:
I want to discuss systems in the world. For this particular discussion, I want to highlight a specific framing through which I will analyze these systems: what is the relationship between cause and effect?1 Specifically, are we able to determine causes for effects we observe?
Non-Complex Systems
Dave Snowden highlighted three types of systems in the Children’s Party video: Chaotic Systems, Ordered Systems, and Complex Systems. I’ll start with Ordered Systems, which are most familiar.
In the framing of cause and effect, an Ordered system is one where the relationship between cause and effect can be determined. This relationship is either clear, or can be discovered through analysis.
An example of a clear relationship would be you clearly knowing that if I hold out an apple in my hand and let it go, it will fall to the ground. It is clear that gravity (or “things fall”) combined with me letting go is the cause of the apple hitting the ground. The relationship between my letting go and the apple hitting the ground is clear to any reasonable person.
An example of a relationship requiring analysis would be me going to a car mechanic to figure out what’s wrong with my car. If the problem is not clear to the mechanic, they would run some tests, analyze the problem, and likely determine the cause of the problem, thus discovering the cause and effect relationship in the system (my car).
For Chaotic Systems, a relationship cannot be determined between cause and effect. Imagine that I am walking in the park and the trees around me start exploding, this would be an example of a chaotic system. I don’t know why there are explosions, and it does not matter. I must act to extract myself from the situation.
Hindsight
In a Complex System, the relationship between cause and effect has a fascinating property, it is only knowable in hindsight. This may be difficult to imagine the first time, but I think you’ll notice it is quite common once pointed out.
If one year ago, I were to ask you what you would be doing right now (reading this), would you be able to predict it? What will you be doing exactly one year from now? That is an impossible question to answer. Now, if instead I were to ask you about the various things over the past year that led you to this moment, you’d be able to tell me (I assume you have a really good memory 😄). This is an example of a relationship between cause and effect that is only knowable in hindsight. This is the nature of cause and effect in a complex world.
What Do You Think?
Do you have examples of complex systems in your life? Do you have examples of systems that are not complex? Let me know in the comments.
Next Up
In this post, I described complexity through the framing of cause and effect. Next, I’ll introduce other frames to help distinguish complexity: Cynefin Complexity.
1 I am sharing small pieces of Dave Snowden’s Cynefin framework, which I’ll write about and link to more directly in the future.
Optimize For Learning…
Principles and Values: Secondary and Tertiary Principles

In the last post, I shared my primary principle: We want to thrive in a complex world. While I found this to be a great overall orienting principle, it is only an aspirational statement. As such, it is a few steps removed from actionable advice.
Optimize For Learning
One effective way of making sense of a complex1 world so that we can act in it2 is to optimize for learning, my secondary principle. A complex world changes from moment to moment. Taking appropriate actions in such a world requires constant learning. It may be beneficial to learn stable patterns or how things generally work. At the same time, we need to keep learning if those stable patterns we learned are now changing into different patterns. Learning never stops. How do we optimize for it?
Tertiary Principles
Effective communication, short feedback loops, systems awareness, and diversity of perspectives are the four tertiary principles that inform how I optimize for learning.
I strive for effective communication because we’re in this together. As the primary principle states, for me to thrive, we must thrive. I believe we need to effectively communicate to coordinate between each other.
The speed/duration of feedback loops constrains how fast I can learn. The shorter the feedback loop, the faster I can learn if my actions had desired outcomes. The longer the feedback loop, the longer it takes to learn. If the feedback loop is too long, learning may not occur at all.
By systems awareness, I intend the need for understanding that we operate within multiple interacting systems which continually modify our constraints and actions available to us. My actions may have no consequence, some consequence, or vast cascading unforeseen consequences good, bad, or otherwise. I believe having this awareness facilitates learning and reduces the mystery of the world a bit.
Diversity of perspectives is needed for my learning to not get stuck in some local optimum. Each of us takes a different path through life. We are each on our very own epic journey. You all know things that I will never experience. If I am to make any claim of optimizing for learning, a diversity of experiences and perspectives is a must.
People Are the Ones Who Act
Because we are people, I believe it is important to always remember that people are the ones who act in the world. In the military, there is a saying: “people first, mission always”. It is far too easy to get stuck behind a facade of numbers on a spreadsheet and forget that there are people on the other side. Let’s never forget.3
What Do You Think?
Do these principles make sense to you? Am I missing a principle that I should include? Let me know in the comments.
Next Up
I’ll start the journey into elaborating on what I mean by complex: A Complex World.
1 I will elaborate on what I mean by complex in future posts.
2 Making sense of the world so we can act in it is a definition of sense-making, by Dave Snowden, “Trespassers W” (blog post, 28 Feb 2021), https://www.cognitive-edge.com/trespassers-w/ , accessed on 1 Mar 2021.
3 This is a reason why I dislike the term “resources” when applied to people. I borrow from the military vocabulary of personnel/materiel and always strive to distinguish people/personnel/staff from resources.

We Want to Thrive in a Complex World
Principles and Values: Primary Principle

A principle is “a fundamental truth or proposition that serves as the foundation for a system of belief or behavior or for a chain of reasoning.”1 My primary principle is:
We want to thrive in a complex world.
What is primary about it? I mean primary in the sense that this is the first principle. I take this principle as an axiom. I can think of no firster [sic 😉] principles than this.
One consequence of this being the primary principle is that I cannot provide an explanation for it. It just is.2
We Want
This used to be a self-centered principle. It used to state I want instead of We want. I always acknowledged that for me to thrive, others must also thrive, but I felt it was less presumptuous to speak only for myself than all of us. Ultimately, we communicates the principle and its intent better and serves as a reminder that we’re in this together.
to Thrive
The word thrive is very intentional here. I believe it is not sufficient to only persist or endure. Please do not misunderstand. It may be the case that the best we can do at times is persist or endure. This is not a judgement that people doing that are somehow lesser. Thriving is an aspirational statement.
in a Complex World
This is such a simple phrase, but here be multitudes and here be dragons. I found that complex means a lot of things to a lot of people. What I mean by complex is very specific and it will take me multiple posts to communicate the exact essence of the concept. The picture of a jungle is a hint. I’ll return to complexity in depth later on, after going through the remaining principles and values.
What Do You Think?
Do you have a primary principle? Let me know in the comments.
Next Up
1 Google Dictionary (“define principle”), accessed on 27 Feb 2021.
2 While I cannot provide a cause for a primary principle, there was a process that allowed me to stumble across it and articulate it to myself. In the first part of How to Do Things, I mention that “I want to thrive in a complex world” resulted from answering the question of “how should I do things?”.
Onboarding to a Software Team: In Three Parts

I usually work in software development, or “tech”. Specifically, I work in web services type of software development. This is an important highlight, because it is a different environment from, for example, designing software to specification to go on a space probe to another planet. Mistakes in web services type of software are not desirable, but they’re also not catastrophic.
This onboarding series is a summary of the things I found effective for me and (maybe?) the teams I participate in. The format is the way I usually present these things, which is, onboarding a new team member onto the team. It consists of three sections: Principles and Values, Team Processes, and How To Deliver Work.
Principles and Values
My friend and colleague Leora Pearson and I had the opportunity to create a team from scratch. This gave us the chance to sit down and think through our principles and values. It was a hugely valuable exercise to think from first principles as to why we were going to build a team and engage in the work. This is a lot of mental models, abstractions, framing, and techniques that help to align the team: complexity, Cynefin, how systems fail, black swans, metaphors, finite and infinite games, Wardley Mapping and doctrine, and Universal Scalability Law. I’ll share these Principles and Values in future posts.
Team Processes
As part of creating the team, we agreed on Team Processes. There are two processes that I find fundamental: the Advice Process, and the Conflict Resolution Process. I’ll share more on these in future posts as well.
How To Deliver Work
Lastly, having Principles and Values and Team Processes in place, I’ll share the ideas around how we organize to deliver work. These will include minimizing cycle time, setting commitment expectations, defining work items, defining failures, tracking ideas, system to human communication patterns, feedback loops, and learning documents.
Next Up
- Principles and Values
More posts on Principles and Values, coming soon.
Microdoctrine: Wardley Doctrine Piece by Piece
Wardley Doctrine is a doctrine developed by Simon Wardley within Wardley Mapping.
“Doctrine are the basic universal principles that are applicable to all industries regardless of the landscape and its context.”
https://medium.com/wardleymaps/doctrine-8bb0015688e5
There is a lot of doctrine. It consists of 44 principles, many of which are entire topics onto themselves. Many writings on doctrine exist. Simon provided these under the Creative Commons Attribution-ShareAlike 4.0 International License. There are many ways to learn doctrine.
I wanted to experiment with the structure of doctrine. I hoped that I could structure it to make it easier to learn and adopt. I want to be able to assess my level of doctrine adoption. And, if I am adopting doctrine, I want to know what I should adopt next. With these goals in mind, I set out to create a doctrine format that breaks up doctrine into small pieces. I call this microdoctrine.
Microdoctrine takes inspiration from a pattern language. It organizes around the principles outlined by Simon. It breaks up those principles into specific practices for individual learning. For example:
Phase: Stop Self Harm
Category: Development
Principle: Focus On User Needs
Practice: Examine Transactions
Motivation:
Any value we create is through meeting the needs of others. A mantra of “not sucking as much as the competitors” is not acceptable. We must be the best we can be.
Consider these first:
Know Your Users
Illustrative description:
Look at the transactions that an organisation makes with the outside world. Examine the customer journey when interacting with those transactions.
Detailed description:
Look at the transactions that an organisation makes with the outside world. This will tend to give you an idea of what it provides and what is important. Next, examine the customer journey when interacting with those transactions. Question this journey and talk with customers. You will often find pointless steps or unmet needs or unnecessary needs.
Another mechanism, if you adopted Wardley Mapping, is to map out the user’s landscape. By mapping out their landscape, you can often clarify what the user needs. You can also find entire new opportunities for business.
STOP READING, TAKE ACTION
Consider next:Align Value Generation With User Needs or Consider Stage of Evolution
“Consider these first” and “Consider next” links express sequencing. This is to answer what principle to adopt next. This also intends to provide immediate benefit. At the same time, it intends to build up ability to adopt future practices.
I completed the first nine doctrine principles in microdoctrine format. These make up Phase I: Stop Self Harm. They are all listed on the Wardley Mapping community site. The starting place is Phase I : Development : Know Your Users.
I can imagine us, doctrine practitioners, organizing around the microdoctrine structure. Each of us could contribute our specific expertise. For example, Phase I : Communication : Challenge Assumptions practices all deal with Spend Control. An expert on Cynefin could contribute a Phase I : Communication : Challenge Assumptions : Ritual Dissent practice for us to consider. My hope is that microdoctrine provides minimal scaffolding for us to organize around.
What do you think? Is this structure useful for learning or assessing doctrine? Are the existing patterns valid? Do you want to add patterns you know about?
