Category: Uncategorized
Introducing Phase Line Mapping
TL;DR Phase Line Mapping is like Wardley Mapping, but at a smaller scale, the scale of projects or initiatives. Instead of the evolution axis, we have a phase line completion axis.
Phase Line Mapping attempts to bring topographical intelligence to project management, similarly as to how Wardley Mapping brought topographical intelligence to business strategy. Taking the classic tea shop Wardley Map, let’s assume we decided to replace the custom kettles we’re building with a supply of commodity kettles.
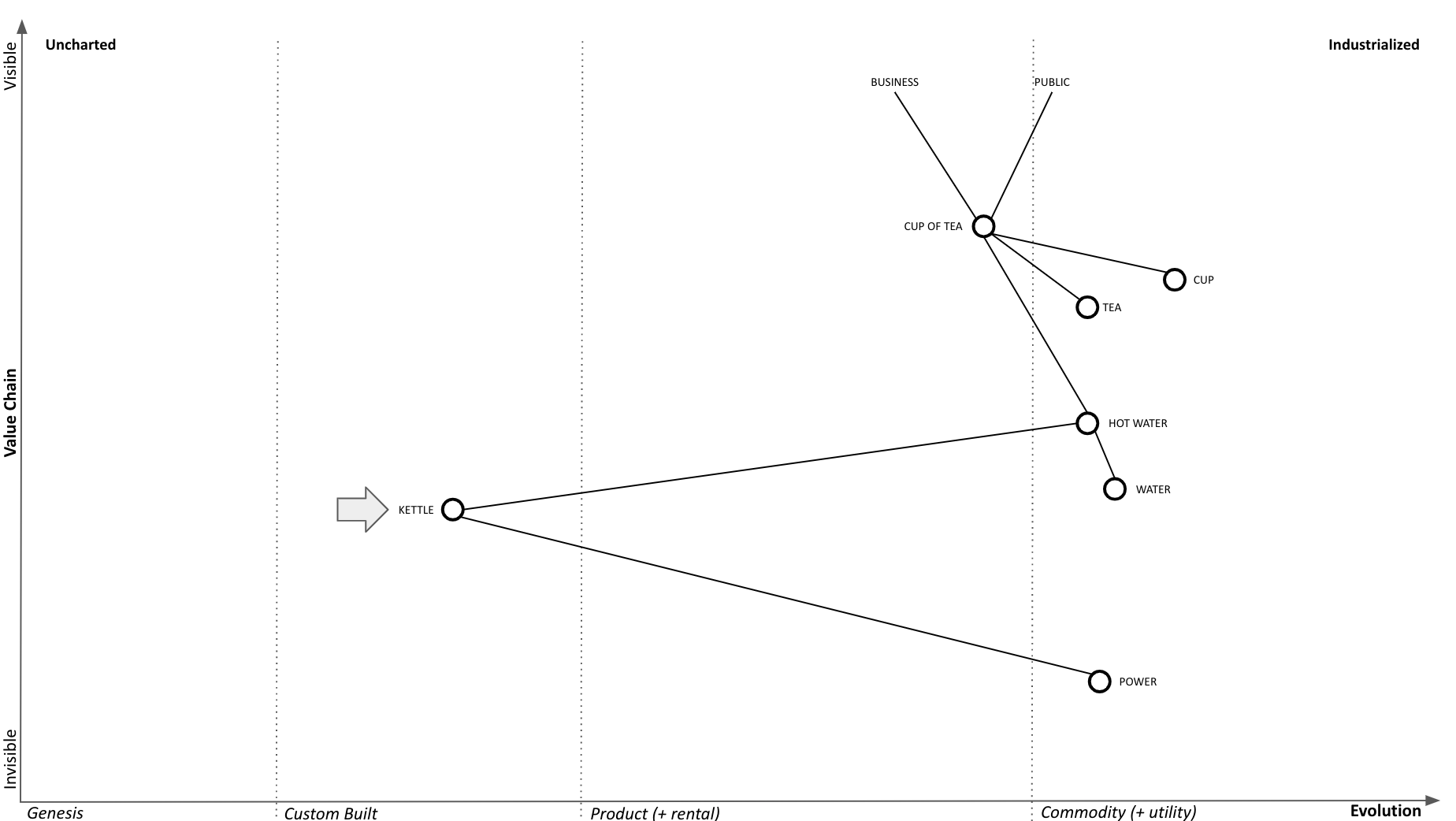
Phase Line Mapping
A phase line is a synchronization mechanism that is similar to a milestone but different from a due date. It depicts changes in the phase of an operation without using dates, therefore, making it possible to coordinate without coupling to the calendar.
Phase Line Mapping retains the value chain scaffolding as the y-axis, in order to keep the project anchored to the outcome it is supposed to provide, while substituting phase line completion axis for the evolution axis:

We conduct vendor selection by trying out a few vendors (SuperKettles, HotKettle, and battery powered KettleGo):
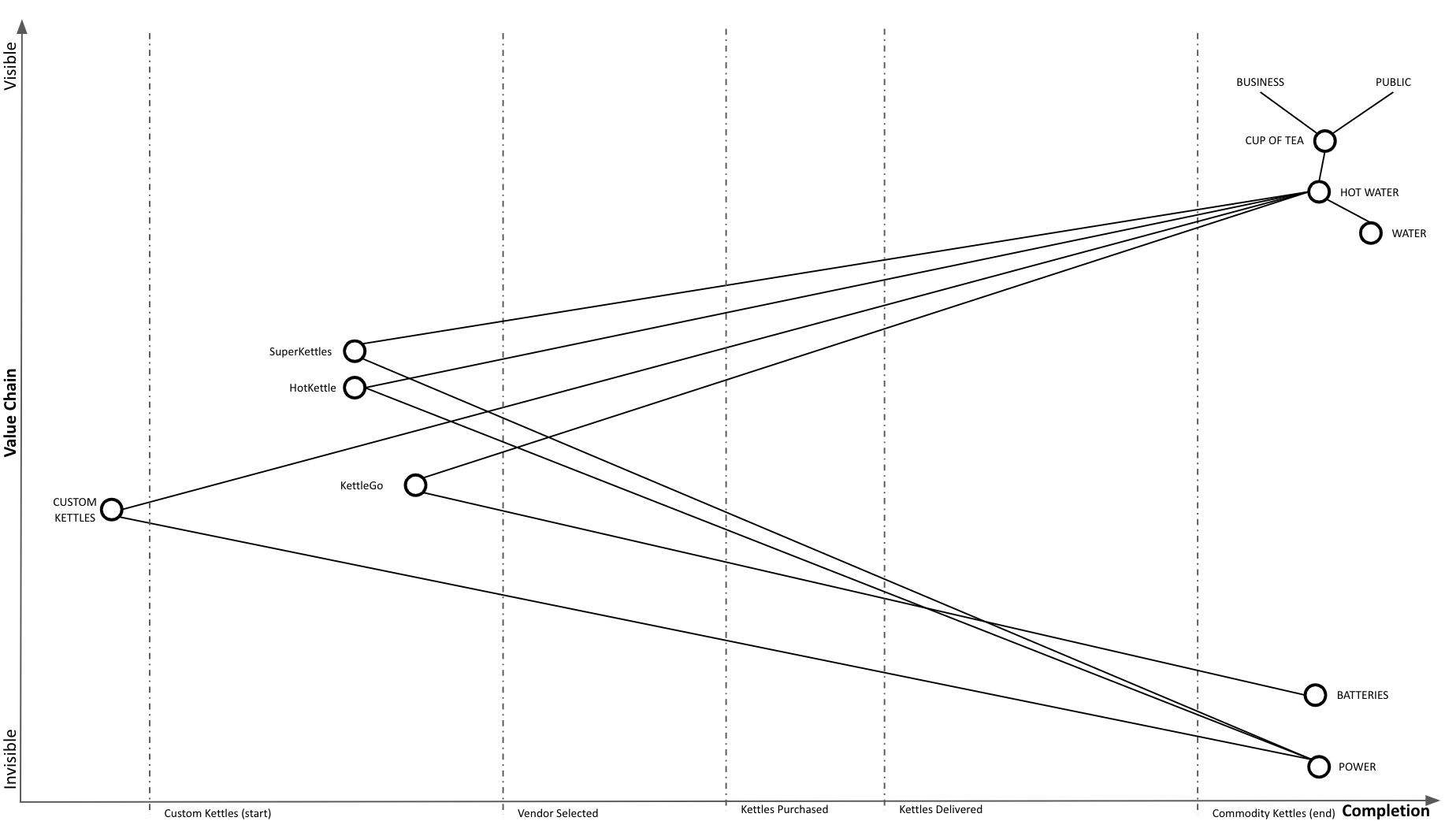
We determined that HotKettle has the right stuff and select them as our vendor. We go through the purchasing process. Notice that we continue to use our custom kettles throughout:

We are hitting some snags with purchasing, but we’re almost there:

Purchasing complete, awaiting delivery:

New HotKettle kettles delivered:
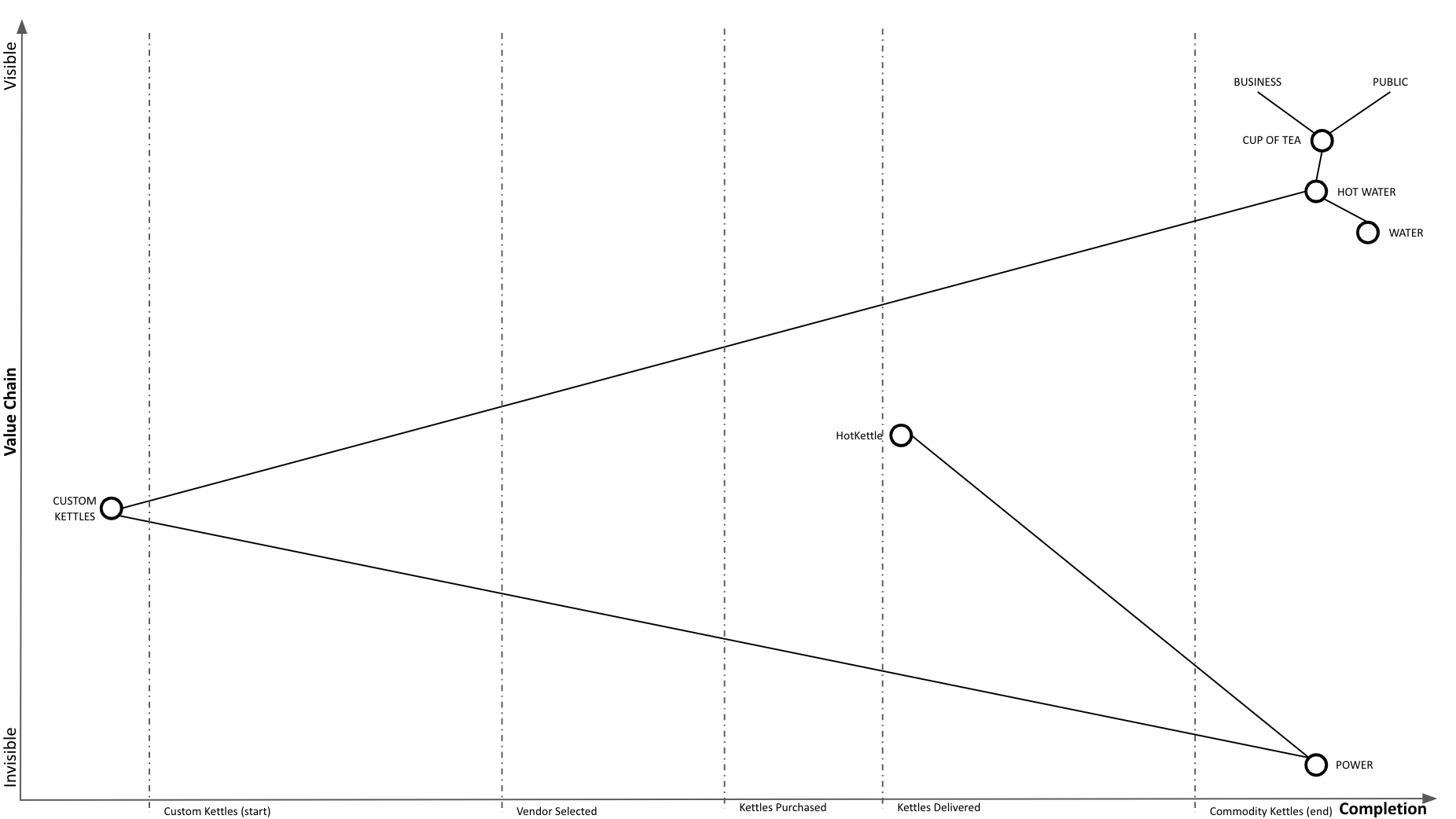
We started our replacement in-place process and are now using HotKettles as well as custom kettles:
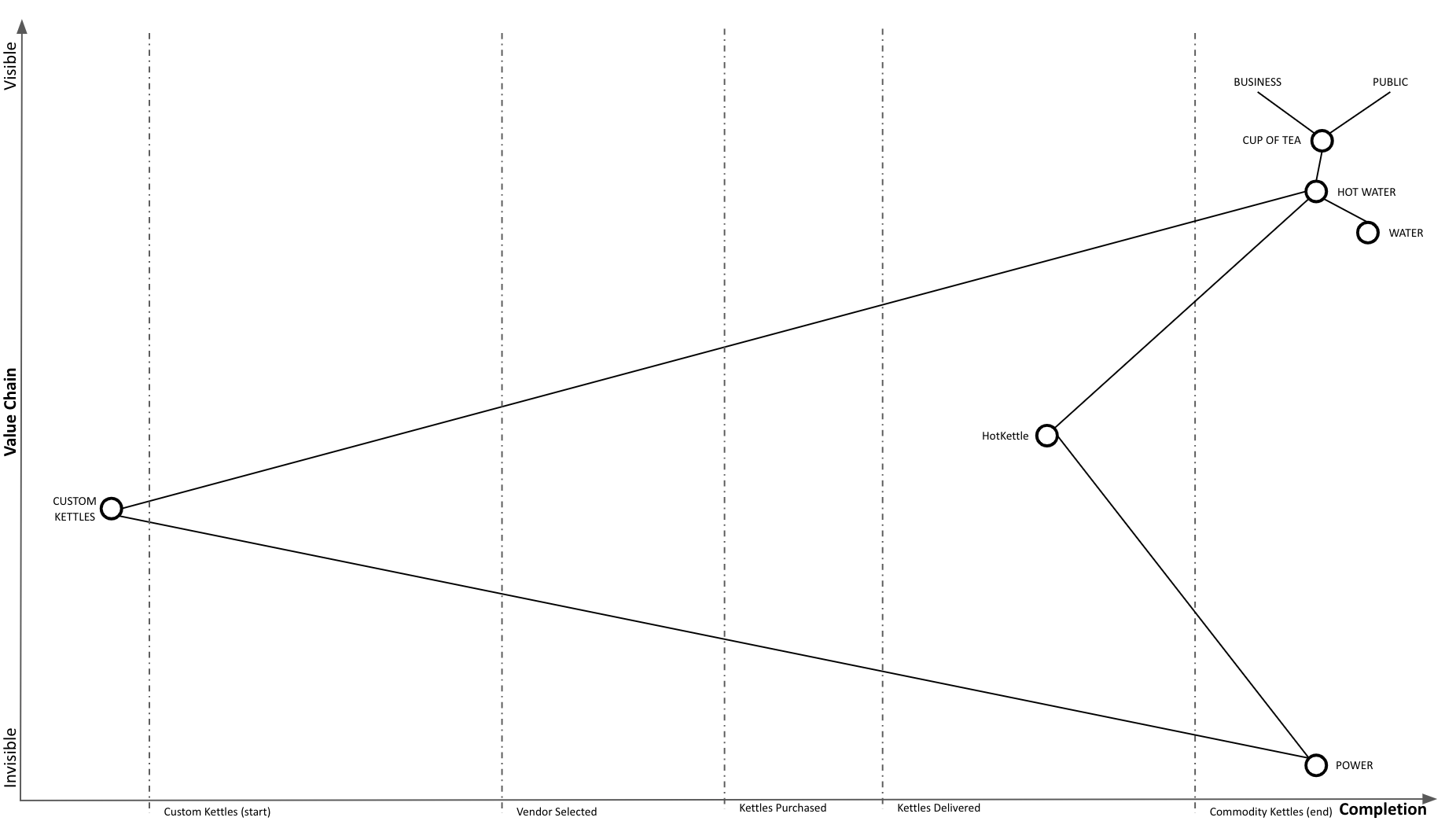
Our adoption of HotKettles is complete:
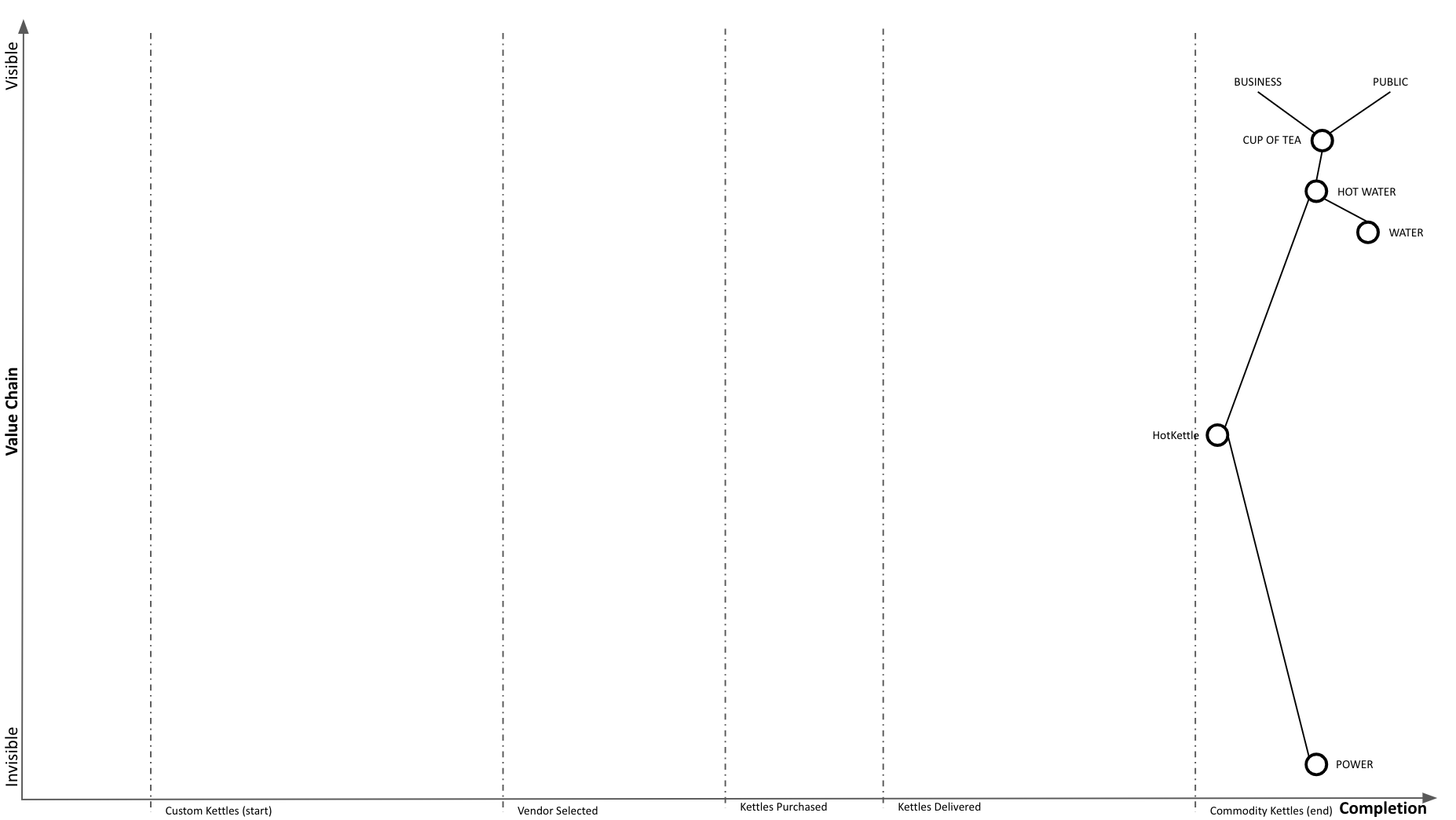
And at Wardley Mapping scale, we completed our transition to commodity:

Phase Line Mapping retains the required elements of a basic map. It is visual, context specific, position has meaning, it is anchored in user needs, movement is present (across phase lines, instead of evolution), and it has components.
Phase Line Mapping has at least two of the three elements of an advanced map. It demonstrates flow between components and can represent different types of things. I am uncertain about what the project level climate looks like or if a stable climate exists. That remains to be seen.
Why?
I have made multiple attempts to share Wardley Mapping. Wardley Maps were intuitive and obvious to me (once I saw them), due to my life experience with topographical maps. However, my experience is not a shared context, and I found it difficult to communicate the value to someone who didn’t immediately “get it”.
The thinking with Phase Line Mapping is that many organizations are executing many projects and programs and are communicating progress in multiple custom ways. Phase Line Mapping is yet another (custom) way to demonstrate project progress across milestones. However, the hope here is to demonstrate mapping that is coherent with Wardley Mapping (same elements, things still move to the right), but where the feedback cycle is much quicker than your typical Wardley Map time scale. It can take years for things to move on a Wardley Map. By introducing a phase line axis, we can generate more feedback loops quicker while training people in Wardley Map intuitions.
My hope is that by being able to demonstrate Phase Line Mapping more broadly in projects, perhaps then, it will be easier to introduce a Wardley Map by saying: it’s like Phase Line Mapping, but at a larger scale, the scale of business. Instead of the phase line completion axis, we have an evolution axis.
An Experiment with Corporate RFCs
I was searching for an RFC-like or an ISO-like structure that defines a particular type of organizational processes. I did not find one, so the Corporate RFC (CRFC) (for example: CRFC2) is an experiment to see if structured specifications like that would be useful.
In software development, I came across RFCs and found them surprisingly effective in communicating protocol specifications. At the same time, being part of a large-enough organization, I find myself in need of being able to communicate heuristics and approaches to organizational practices that I found useful over time, for example: PRFAQ, Toyota A3, OKRs (still unsure about the utility of this one). PRFAQ, popularized by Amazon, doesn’t even have a Wikipedia entry at the time of this writing.
Introducing a new organizational process takes time and lots of mentorship. However, part of the work to introduce a new process is all of the documentation required to communicate and establish the process. It seems to me that each one of us attempting this, is building custom documentation for a supposedly well-known process we are attempting to introduce. This is what I was searching for, some sort of standard documentation of a well-known process that I wouldn’t have to extract out of a series of blog posts, books, or courses. This is where my experience reading and using RFCs pointed at a possible approach.
One of the things that I find useful about RFC-like structure is that it seems to function toward the commodity end of the Wardley Evolution axis.

Another thing I find useful about RFC-like structure is that it is not a regulatory standard, and therefore not subject to licensing or certifications that I know of.
As mentioned and depicted on the image above, I understand the current state of the art for describing organizational processes to consist of blog posts, ad hoc agreements within organizations on an organizational standard (for example: standard way to do design reviews). Additionally, there exist certifications and licensed frameworks; the ones that come to mind are commercializations of Agile, but surely there are others. Then there are regulatory standards that are the cost of doing business like PCI, GDPR, etc.
I’m thinking that CRFC could be a way to provide RFC-like commodity specifications that we can share for the types of organizational processes that are not regulatory, but that summarize good or best practices within organizations. Their intended use would be as references to specific protocols that an organization wants to implement. Their specific scope would be somewhere between saying the phrase “PRFAQ” and writing down explicit patterns one can find for business processes in workflowpatterns.com.
Perhaps the best way to illustrate where a CRFC would fit in is by example, so there exist two initial examples for reference: CRFC2 and CRFC1.
If you’re interested in these types of specifications, the list of existing CRFCs is available at https://github.com/corporate-rfc/.
If you’re interested in contributing, the initial thoughts on contributions are available in https://github.com/corporate-rfc/DRAFTS.
Map/Serverless/DevOps DaysATL 2019 Things Learned
There are lots of things I learned at Map/Serverless/DevOpsDaysATL 2019 that I will probably not mention here, but I do want to share a random set of highlights that I’ll probably want to reference myself in the future.
What Wardley Maps really look like
It turns out, that most practicing mappers, including Simon Wardley himself, use maps in a way where the generated artifact looks like this:
This wasn’t at all obvious to me when reading the mapping book and learning about mapping in general. The pretty versions of maps in the book, in presentations, etc.. are that way mostly* to teach others about mapping. After all, the picture above would be a difficult pedagogical tool.
* some maps are worth presenting or keeping around and iteratively come back to them; also, digital maps allow for long-distance collaboration; however, most maps probably look like the picture.
Vertical axis of a Wardley Map is… kinda there
There is a lot that goes into explaining the horizontal evolution axis of a Wardley Map. Multiple adoption cycles, diffusion of innovation, all sorts of things come into play. It takes a lot of research to determine the stage of evolution, and we usually bypass it via crowdsourcing of people’s opinions. I even created https://mappingevolution.com to help me figure out where things ought to go. The value chain vertical axis, on the other hand, is there as “scaffolding”. People kept asking Simon what is the vertical axis so it is what it is. Movement on the vertical axis, while meaningful, seems to me to be much less meaningful that movement on the horizontal axis. However, Jabe Bloom framed the vertical axis in an interesting way using Regimes, Strategies, and Niches.
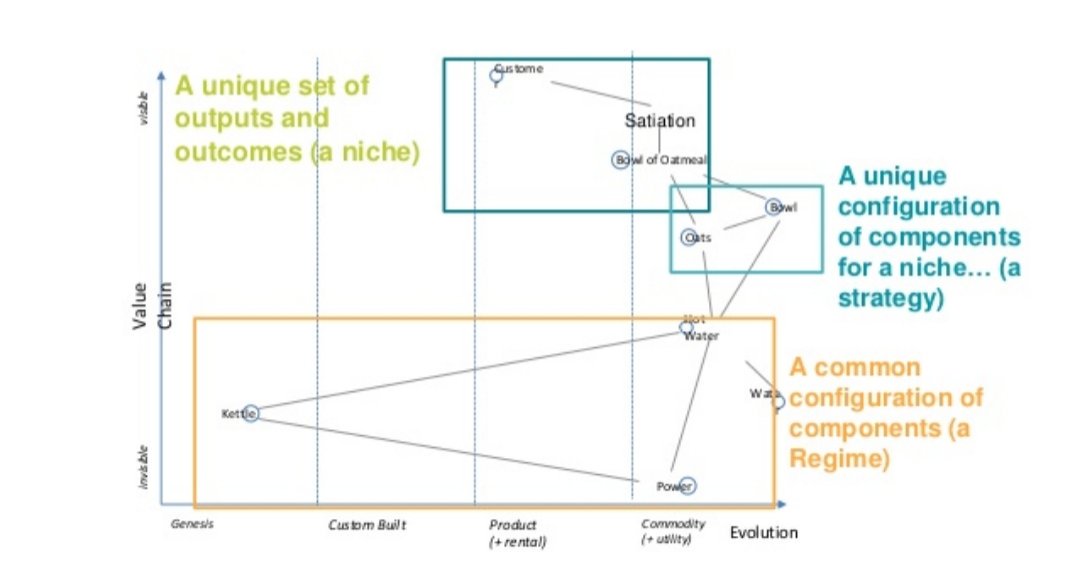
I haven’t fully grokked this framing yet, so I’m uncertain if it is useful. However, I am intrigued.
Burja Mapping
Tasshin Fogleman introduced Samo Burja’s Empire Theory and created a sort of mapping for power structures in human organizations.
I have more reading to do, but Burja’s ideas on top of some sort of Tasshin’s mapping are intriguing.
Spatial visualization of framing
As always, Jabe explains some philosophy in a very accessible way. In this case, I really enjoyed his visualization of framing. It is also the first time in my mind it clicked that framing can be interpreted as figuratively putting a picture frame on some part of reality and considering what is in the frame. I always understood framing abstractly, but not this spatially.
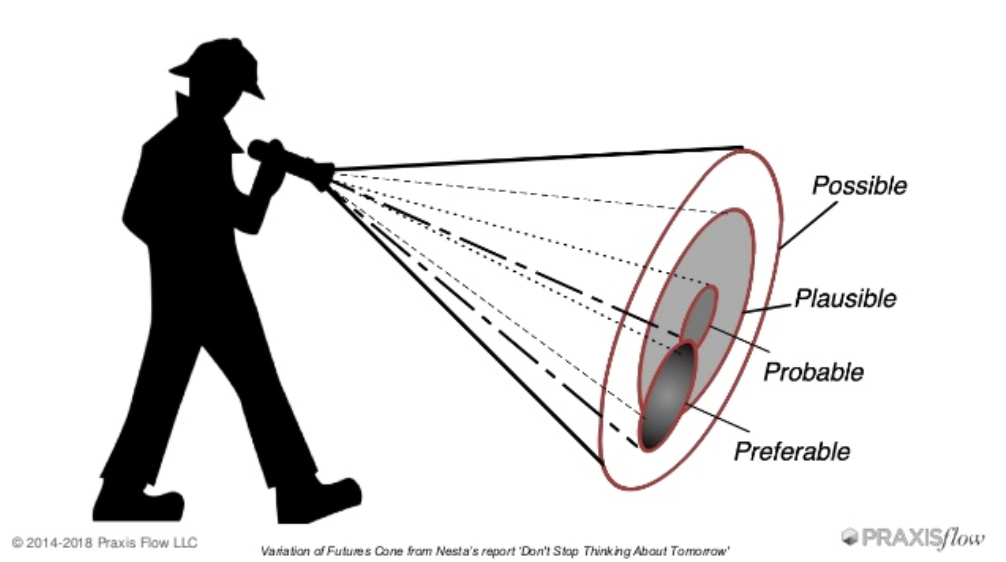
Output and Outcomes
Also from Jabe’s presentation, this was an important highlight, that both outputs and outcomes should be on the map.
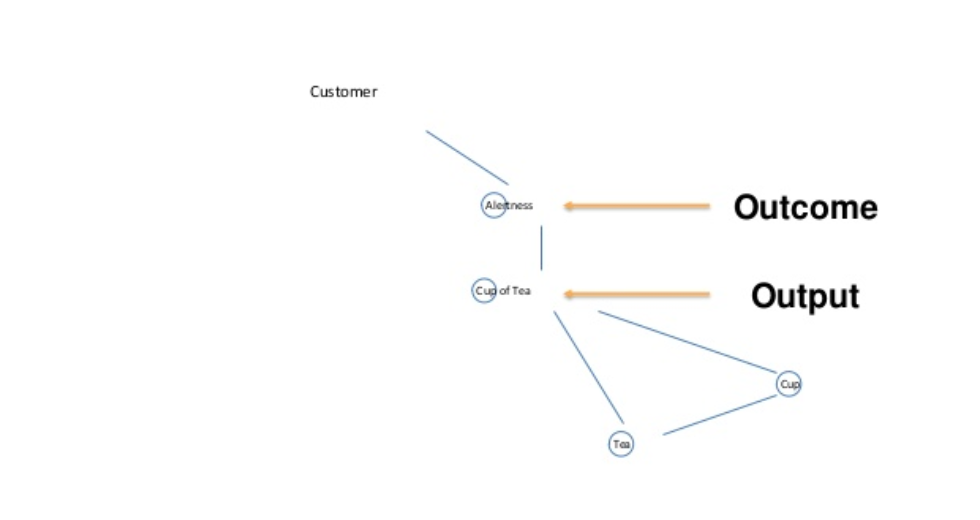
Cost of Change
Also also from Jabe’s presentation, he highlighted three types of change to keep track of on a Wardley Map. In particular, not only the change of a component on a map, or the change due to movement of component on a map, but the change due to changing relationship between components, the changes in lines on a map and what components the lines link.
Contracts/Pacts
I got to sit out of frame and hear Claire Moss talk about contracts and pacts. I’ve heard of these before, but she highlighted multiple nuances that I wasn’t aware of. Definitely provided additional context for my thoughts on the boundary between Complicated and Complex. You can find the discussion on Twitter.
And lots of other things…
Aside from some of the highlights above, I was fortunate to meet a bunch of people who I only ever saw on video and have conversations with them. That was definitely the highlight of the conf.
Now, I have some reading and thinking to do…
The Hidden Cost of Collaboration -Resource Contention
This post explores why the speed of software development can slow to a crawl inside large organizations. In particular, we will consider software services and their customers from the perspective of resource contention. It turns out that this framing highlights a major contributing factor that slows software development. We will conclude with what can be done about it.
Consider the problem of resource contention. Software services require resources to operate, and those resources are finite. When users use a software service, resource contention problem occurs as soon as there is more than one user. The key question to consider is, who is responsible for managing the resource contention problem? We have two possibilities. The service itself can manage the problem in a centralized way or the users can manage the problem in a decentralized way. This is the key insight to extract from this framing.
The service itself can manage the problem in a centralized way or the users can manage the problem in a decentralized way.
The resource contention problem can be managed by the service or by the users. In the case of the service, the management can be centralized within the service. In the case of the users, the management must be distributed.
There is a cost associated with managing the resource contention problem.
When the service bears the cost, it bears the entire cost of managing the problem. A typical solution to the resource contention problem is for the service to become multi-tenant. To every user, it seems as they are the sole tenant of the service and need not worry about managing resource contention.
When the users collectively bear the cost, the cost for any single user is mostly small, most of the time. A typical solution takes the form of an ad hoc, distributed, and probably incorrect, consensus protocol. This protocol is typically referred to as “careful” or “being a good citizen.” Every user knows that there are other users who at any point can do something that severely degrades their own use of the service, or worse, they’re unaware of it. Typically, users coordinate with each other in order to manage the shared service and not exhaust its resources.
Consider what happens when a user uses multiple services for which they have to manage resource contention with other users. Every new service requires adoption of a new, ad hoc, distributed, and incorrect, consensus protocol. While the cost of coordination may be low initially, the cost, per user, grows super-linearly with the number of services used, since all of the users of each new service, some of them unknown, must be coordinated with.
Alternatively, when each service manages the resource contention problem by offering multi-tenancy, every new service requires no coordination from the user. The cost, per user, increases linearly with the number of services used and is limited to learning how to use the service.
When each service manages the resource contention problem by offering multi-tenancy, every new service requires no coordination from the user.
Another relevant concept in the dynamic between services and users is the notion of internal and external users.
Users external to the business, tend to have other options, and therefore are less likely to put up with additional cost of coordination required for using the service. On the other hand, internal users typically have no such luxury, are cost insensitive, and must use the service designated for them. This tends to lead to a pathology where the service seems justified in not paying the additional cost of providing multi-tenancy, as the internal users have to use the service no matter the cost of coordination. But, what is often missed, is the super-linear cost the internal users must bear for their distributed management of resource contention. Fortunately, there are things we can do to avoid this situation.
Service seems justified in not paying the cost of providing multi-tenancy, as the internal users have to use the service no matter the cost of coordination.
We can demand that all services manage the resource contention problem by being multi-tenant. Alternatively, we can ensure that internal customers have a choice of using or creating another service that is multi-tenant, which may eventually lead to multi-tenant services as the cost of their adoption is lower.
Lastly, I want to highlight a pathological move not to make.
Forcing the use of a single service is the right move if and only if that service is multi-tenant.
There is great efficiency to be gained by removing duplication of effort. Forcing the use of a single service is the right move if and only if that service is multi-tenant. Otherwise, the organization is placed in a configuration where internal users must bear the cost of managing resource contention and cannot improve their situation by using a multi-tenant alternative.
Explain Types (In Programming) As If I Was A Normal Person
What is a type?
Something, something, computer programming…
What I find interesting about types is that they enable me to think in terms of patterns as opposed to in terms of specific examples. A type system, allows me to express something in terms of patterns, and the patterns can be arbitrarily abstract. Ironically, let’s look at some examples of patterns, i.e. types.
Unit type
A Unit type can be thought of as a pattern of “something”. It conveys the notion that “something” exists. There is an instance of “something”.
It may help to think in terms of receiving an email in your inbox, but that you only saw the number of new messages increase by one. You haven’t read the email. You know nothing about it. You just know that you have another email in your inbox. That’s like Unit type. It conveys that “something” (some email) exists.
I tend to think of Unit type as a “signal”. If you imagine a light switch, a “signal” is not whether or not the light is on or off. A “signal” would be the flipping of the switch, the flip itself. Imagine you can’t see the light, you just hear the switch flipping. flip flip flip… three signals, three Unit types.
Ok, that might still be fairly abstract. Let’s contrast this with something more familiar, but let’s name it something really weird, like, the Sum type.
Sum type
A Sum type can be thought of as “exclusive or” pattern. In other words, it can be this “something”, or that other “something”, but not both. For example, consider the notions of True and False. We say that something can be True or False but not both.
In fact, True or False (but not both) is of the type Sum with the shape of Unit + Unit. “Unit + Unit” means that the Sum type has space for two Units, but the fact that it’s exclusive or, means that it will only accept one Unit. True is defined by putting “something” (of type Unit) into the first space of Unit + Unit. False is defined by putting “something” (of type Unit) into the second space of Unit + Unit. What if you want to put “something” into both? You can’t, because by definition, we say that you can only put “something” into one of the spaces. Why is True putting “something” into the first space and not the second? The answer is that that’s the convention that most people who use Sum types use. You can use any convention you want, but it may be more difficult to understand what you’re communicating.
Remembering that Sum type describes a pattern of “exclusive or” helps me to remember how it works.
Going back to our light switch example, and to illustrate the difference between Sum and Unit, imagine that we now can tell whether the light is on or off. We can represent the pattern of knowing whether the light is on or off by Sum type with the shape Unit + Unit. If light is on, we will put “something” into the first space. If light is off, we will put “something” into the second space. It can’t be both on and off. All we need to put into one of the spaces is of Unit type, a “signal”. Remember that it is not the “signal” that tells us the light is on. The space the “signal” is in is what tells us whether the light is on or off (first space means light on, second space means light off). The nature of the “signal” itself is immaterial, we only care that “something” is in the space.
Why is it called “Sum” (as in “summation”) type? The name comes from how one would calculate the number of unique things that one can represent using a Sum type. For example, the Sum type Unit + Unit, can represent only one plus one, that is, two things. This is why it’s used for representing True and False, as those are exactly two things. If, for some reason, we wanted to represent four things, for example: Spring, Summer, Fall, Winter, I could use a Sum type of Unit + Unit + Unit + Unit. One plus one plus one plus one is four. And a season can (for our illustration purposes here) be either Spring, or Summer, or Fall, or Winter, but not more than one of those.
Product type
A Product type can be thought of as “and” pattern. In other words, it can be this “something” and that other “something” together.
A Product type that has two “somethings” would be Unit x Unit. “Unit x Unit” means that the Product type has space for two Units (“Unit x Unit x Unit” would mean that the Product type has space for three Units). For example, a weekend is Saturday and Sunday. We can represent Saturday by putting “something” into the first space and Sunday by putting “something” into the second space. Now, this is a somewhat not useful example of a Product. Let’s come up with a better example.
Remember our Sum type of Unit + Unit where we defined True and False? Let’s name that particular Sum type shape of Unit + Unit a Boolean type (it’s named after George Boole). Now that we have our Boolean type (which represents the notions of True and False), let’s define a more useful Product of the shape Boolean x Boolean. “Boolean x Boolean” means that the Product type has space for two Booleans. We’ll still think about the weekend, but this time, the first space will represent whether we are working on Saturday, and the second space will represent whether we are working on Sunday. So, if I’m working on Saturday and Sunday, I would represent that as True x True. If I’m working on Saturday, but not working on Sunday, I would represent that as True x False. Not working on Saturday, but working Sunday would be False x True. And, lastly, not working all weekend would be False x False.
Why is it called “Product” (as in “multiplication”) type? That’s because to calculate the number of unique things that one can represent using a Product type, we multiply the number of things that can be in the first space by the number of things that can be in the second space and so on. Notice, in our weekend representation of Unit + Unit, we could only put one thing in each space (Saturday and Sunday), so the number of things we could represent was one times one is one, the weekend. However, once we could put two things into each space, as in our example of whether we are working on the weekend, we could put two things into first space (True, False), and two things into second space (True, False). Two times two is four, and the Product type of Boolean x Boolean could represent four different work schedules over the weekend.
Void type
A Void type can be thought of as a “nothing” pattern. This pattern is either obvious to people, or very difficult to understand.
In the email inbox example, a Void type means that an email hasn’t arrived. You received no signal, “nothing” happened, no change at all.
In the light switch example, a Void type means that you can’t see if the light is on or off, and you can’t hear the flipping of the switch. It’s not that you will eventually hear or see something, but not yet. It’s that you will never hear or see anything. “Nothing” will happen. Void is the absence of any signal.
We now have some understanding of other types that can help us understand the nature of Void type. Imagine I have a Sum type with the shape of Void + Unit. “Void + Unit” means that the Sum type has only one space, and it is only the second space. There is no first space in Void + Unit type. How many things can you represent using Void + Unit type? It is zero plus one. You can only put zero things into the first space, because there is no first space. There is only second space, into which you can put one thing. Void type is analogous to zero.
To see this another way, consider a Product type of Void x Unit. How many things can you represent using Void x Unit type? It is zero times one, which would be zero. The first space doesn’t exist, it is of type Void, and therefore we have no way of constructing something that fits the pattern of “nothing and something”. The problem is that we cannot construct a something that fits the pattern of “nothing”, so we can never construct a something of Void x Unit type.
Arrow type
An arrow type is a pattern of “how things on the left side of the arrow relate to the things on the right side of the arrow” (but not the other way around). This sounds fairly abstract, let’s dive into an example.
Previously, we used the example type Product of Boolean x Boolean to describe a weekend work schedule. Let’s call this Product type a Schedule type. To build our example, we’ll also consider a Sum type of Unit + Unit, where putting Unit into the first space will mean worker Tristan, and putting Unit into the second space will mean worker Dale. Let’s call this Sum type a Worker type. Now, we can describe an Arrow type of Worker -> Schedule which is a pattern of “how Workers on the left side of the arrow relate to the Schedules on the right side of the arrow”.
Other common names for Arrow type are Exponential type, or Function type. The reason for “Exponential” name, is the same as for Sum and Product types, that is, it describes a way of how to count how many number of unique things one can represent using an Arrow type. Remember that our Arrow type is Worker -> Schedule. Worker type is a Sum type of Unit + Unit, which can represent, one plus one, so two things. Schedule type is a Product type of Boolean x Boolean, which can represent, two times two, so four things. The Arrow (“exponential”) type can represent Schedule ^ Worker number of things, or four to the power of two things, so 16 things. Let’s count them:
- Tristan -> (True, True), Dale -> (True, True)
- Tristan -> (True, True), Dale -> (True, False)
- Tristan -> (True, True), Dale -> (False, True)
- Tristan -> (True, True), Dale -> (False, False)
- Tristan -> (True, False), Dale -> (True, True)
- Tristan -> (True, False), Dale -> (True, False)
- Tristan -> (True, False), Dale -> (False, True)
- Tristan -> (True, False), Dale -> (False, False)
- Tristan -> (False, True), Dale -> (True, True)
- Tristan -> (False, True), Dale -> (True, False)
- Tristan -> (False, True), Dale -> (False, True)
- Tristan -> (False, True), Dale -> (False, False)
- Tristan -> (False, False), Dale -> (True, True)
- Tristan -> (False, False), Dale -> (True, False)
- Tristan -> (False, False), Dale -> (False, True)
- Tristan -> (False, False), Dale -> (False, False)
The reason for Arrow type to be called Function type is that Arrow type corresponds to what people mean by “function” in mathematics. If I have a thing of Arrow type, for instance, Tristan -> (True, True), Dale -> (True, True), then if I want to find out Tristan’s schedule, I would provide Tristan as input to the function, and the function would return the result (True, True).
Why call it an Arrow type then? There is a thing in mathematics called “up-arrow notation”, and it so happens that a single up-arrow in up-arrow notation corresponds to “exponential”. Discussing multiple arrows is out of scope of this post, but mentioned here for the curious.
Value type
A Value type can be thought of as a pattern in contrast to the Unit type pattern. Where Unit type was a “something” pattern, Value type is “this particular thing” pattern.
In the email inbox example, again, by contrast, where Unit type would be a signal that some new email arrived and we only care about the signal. Value type would be saying that a particular email arrived, and while we care that email arrived, we also care about the value, the particular contents of that particular email.
Another way of phrasing this, is that for a Unit type we only care about the signal. In the sentence “This thing exists”, what we focus on in Unit type is exists. For Value type, we focus on the entire sentence this thing exists, because we are trying to express the pattern that particular thing not only exists, but that it is a particular thing.
For example, think of the boolean True. Looking at True through the lens of “this particular thing”, we care that it is True, and that it is not False. The value of True is True.
Type type
Time to get weird.
Type type expresses the pattern of “a pattern” 😬. We covered multiple examples of Type type. Unit is of type Type. Sum is of type Type. Product is of type Type.
There is an important concept to highlight. Earlier, we defined True and False as being of the type Boolean. What’s worth highlighting is that Boolean is of type Type, but True is of type Boolean.
Also, notice that the type Type is of type Type. This is because the pattern of “a pattern” fits the pattern of being “a pattern”.
Everything is a Value
Weirder…
Recall that when we talked about the Value type, we were expressing the pattern of “this particular thing”. If we have the type Boolean, and we have a particular boolean, say True, then the particular boolean True is of type Boolean, but it is also of type Value. This is because the boolean True fits the pattern of “booleans” and it fits the pattern of “particular thing”. “Fitting a pattern” is referred to as “inhabiting a type”. So, the boolean True inhabits the type Boolean and it inhabits the type Value. This is because it “fits the pattern of booleans” and it “fits the pattern of particular thing”.
Types are Values and Values are Types
Meta-weird…
Types are Values. This is because Type type (a pattern of “a pattern”) fits the pattern of being “a particular thing”. The type Type inhabits the type Value.
Values are Types. This is because Value type (a pattern of “a particular thing”) fits the pattern of being “a pattern”. The type Value inhabits the type Type.
Everything inhabits Unit
Notice that the Unit type is the pattern of “something”. This means that everything that exists fits the pattern of being “something”, therefore everything that exists inhabits the type Unit.
It is worth highlighting the interplay of Void type and Unit type. The Void type itself inhabits type Type, inhabits type Value, and inhabits type Unit, because the pattern of “nothing” fits the pattern of being “a pattern” (Type), fits the pattern of being “a particular thing” (Value), and fits the pattern of being “something” (Unit). However, notice that there is nothing that can inhabit the type Void. This is because to fit the pattern of “nothing”, there can be nothing there. If there was something there, it wouldn’t be nothing.
That’s all for now…
Let’s stop before it gets weirder (like thinking about Arrow types with Void types), but this should be a fair introduction to the basic concepts with hints at where things start to get out of hand and we might need something more sophisticated than the english language.
While what I’ve described here (in english) is a description of a type system, there are different type systems that can be described, and they can differ from each other in subtle ways. The differences between them doesn’t make any of the other systems incorrect, nor does it make this description correct. But, hopefully, I managed to communicate some intuition about one kind of type system to you.
If something isn’t clear, please comment/respond and we’ll talk about it.
Also, thank you Dale Schumacher for pointing out errors in the early drafts and thinking through all this stuff with me.
Cheers!
Our Kanban Boards Are Backwards!
If you’re using a Kanban board to visualize your work, in its most general form, it probably looks something like:

It turns out that this is exactly backwards with how we intuitively visualize time. As Jabe Bloom points out, the “set of columns reflects an inversion of our innate understanding of the flow of time.”1 Instead of time flowing from left to right in a Past, Present, Future order, it is inverted, and on a Kanban board it flows from right to left.

Contrast this with what a Kanban board would look like if it was coherent with how we usually think about the time arrow.

Once I rearranged a Kanban board this way, I have a hard time thinking of it differently. There are multiple things that become coherent with this arrangement.
- The new arrangement is coherent with how left-to-right readers visualize the arrow of time. By coherent, I mean a very abstract coherence in the sense that “Happy” is coherent with “Up” or that “Sad” is coherent with “Down”.
- When “walking the board”, we are taught to walk “backwards” from DONE to TO DO. Well, in this new arrangement, there is nothing backwards about it. Walking the board becomes coherent with the board arrangement and the flow of time.
- The cards end up traveling from right to left. For some reason, that is more coherent with “pull”. To contrast with a standard Kanban board, cards traveling left to right seems to me more coherent with “push”.
- Looking at “TO DO” column in the future and on the right, feels more coherent with “TO DO” being our vision of the future that we are “pulling” into reality one card at a time. It also, to me, highlights better my opinion that a backlog is just a place where everything goes stale without us worrying about it.
- The clutter of a “TO DO” column seems easier to dismiss when it’s on the left. When it’s on the right, the clutter of “TO DO” goes from “we have a lot of work to do” to “we have no coherent view of what we want in the future.” The difference is very subtle, but I think it’s there.
Will changing your Kanban board this way make you 50% more productive? No. However, while I see no compelling reason for the predominant TO DO, DOING, DONE arrangement, there seems coherence to be gained by switching to DONE, DOING, TO DO.
Endnotes:
1 Bloom, Jabe (2012). The Moment of Pull – Meditations on time and the movement of cards. Retrieved 9 Feb 2018.
2 While this Kanban board arrangement came to me while reading Jabe’s “The Moment of Pull,” it is not a new idea. For example, see: Rybing, Tomas (2015). Mirrored Kanban Board. Retrieved 9 Feb 2018.
How Long Will It Take? – Part 2 – So, Does It Work?
After writing the original How Long Will It Take? post, I kept wondering how to measure if the estimation method described therein (from here on referred to as “Historical Lead Time”, or HLT) is effective, for some definition of effective. What I realized is, since the estimation method does not require human input, I could use historical data and simulate what the method would estimate at any particular point in time. This blog post describes this experiment and demonstrates a very surprising finding.
TL;DR: It turns out that the HLT method minimizes estimation error better than every other tested method except one, which is… *drumroll*… “pick the average so far” as the estimate. Read below for details and caveats. Also, it would be very helpful to run this experiment on many data sets instead of just the one I used, please contact me if you can provide a data set to run this experiment on.
Experiment Objective
Determine usefulness of estimating software work using percentile estimates based solely on observed past data as described in How Long Will It Take? .
Experiment Hypothesis
HLT estimates are better than random estimates. (Spoiler: they are! … or more correctly: experiment results do not refute this hypothesis)
Experiment Metric
Sum of square error, which will be the difference between estimated duration and actual work item duration, squared.
Experiment Design
The experiment is a simulation of what would the estimates be at specific times in the past. Given a data set of work start and stop times, simulation starts after completion of first work item and ends after completion of last work item in the data set.
Experiment uses multiple estimation models. The model with the least cumulative sum of square error is deemed the best. Where appropriate, models are tracked per 25th, 50th, 75th, 90th, 95th, and 99th percentiles. Models used in the experiment are:
- HLT: Estimation method described in How Long Will It Take?.
- Levy: Estimation method that assumes distribution of observed work item durations can be described as a Levy distribution. This model is included to showcase a terrible model.
- Gaussian: Estimation method that assumes distribution of observed work item durations can be described as a Gaussian/Normal distribution. This model is included to showcase a “dumb” model as a sanity check.
- Random: Estimation method that simply picks a random number between zero and longest duration observed so far. This model is included to provide a baseline to compare against.
- Weibull: Estimation method that assumes distribution of observed work item durations can be described as a Weibull distribution. This model is included because it is seems to be the go-to model used by people who take estimation seriously.
In addition to the above models, each model is also tested with and without sample bootstrap to a sample size of 1000, as described in How Long Will It Take?
Data set used for the experiment is Data Set 1, consisting of 150 work item start and stop times.
Each simulation is performed using the following procedure:
- Using Data Set 1, create a timeline of start and stop events to playback.
- Playback the timeline created in 1.
- Upon observing a work item start event, notify the estimation model of work item start. If the model can generate an estimate (model must observe two completed work items prior to generating an estimate), compare the generated estimate with actual known duration, calculate the square error, and record it.
- Upon observing a work item stop event, notify the estimation model of work item stop.
- Continue playback until the timeline is exhausted.
Experiment Results
A rich way to demonstrate the results is to plot the cumulative sum of square error for each model and each percentile together (model+percentile, e.g.: “levy 0.99”, means Levy model 99th percentile, “hltbs 0.75”, means HLT model with bootstrapped sample at 75th percentile). These plots are included below. In consecutive plots, the worse performing model+percentile line is eliminated so that we can see more detail regarding better performing models. Also, the shape of error accumulation is instructive. The elimination order is (from most accumulated error to least accumulated error):
levy 0.99, levybs 0.99, levy 0.95, levybs 0.95, levy 0.90, levybs 0.90, levy 0.75, levybs 0.75, wbulbs 0.99, hltbs 0.99, wbul 0.99, hlt 0.99, gausbs 0.99, gaus 0.99, levy 0.50, levybs 0.50, gausbs 0.95, gaus 0.95, wbulbs 0.95, rand, wbul 0.95, gausbs 0.90, gaus 0.90, hltbs 0.95, hlt 0.95, levy 0.25, levybs 0.25, gausbs 0.75, gaus 0.75, wbul 0.90, wbulbs 0.90, hltbs 0.90, gaus 0.25, gausbs 0.25, wbulbs 0.25, wbul 0.25, randbs, hltbs 0.25, hlt 0.25, wbulbs 0.50, wbul 0.50, hlt 0.90, wbulbs 0.75, wbul 0.75, hltbs 0.50, hlt 0.50, hltbs 0.75, hlt 0.75, gausbs 0.50, gaus 0.50
Here is a list that performed worse than “rand”:
levy 0.99, levybs 0.99, levy 0.95, levybs 0.95, levy 0.90, levybs 0.90, levy 0.75, levybs 0.75, wbulbs 0.99, hltbs 0.99, wbul 0.99, hlt 0.99, gausbs 0.99, gaus 0.99, levy 0.50, levybs 0.50, gausbs 0.95, gaus 0.95, wbulbs 0.95
Here is a list that performed worse than “randbs”:
levy 0.99, levybs 0.99, levy 0.95, levybs 0.95, levy 0.90, levybs 0.90, levy 0.75, levybs 0.75, wbulbs 0.99, hltbs 0.99, wbul 0.99, hlt 0.99, gausbs 0.99, gaus 0.99, levy 0.50, levybs 0.50, gausbs 0.95, gaus 0.95, wbulbs 0.95, rand, wbul 0.95, gausbs 0.90, gaus 0.90, hltbs 0.95, hlt 0.95, levy 0.25, levybs 0.25, gausbs 0.75, gaus 0.75, wbul 0.90, wbulbs 0.90, hltbs 0.90, gaus 0.25, gausbs 0.25, wbulbs 0.25, wbul 0.25
Here is a list that performed better than “randbs”:
hltbs 0.25, hlt 0.25, wbulbs 0.50, wbul 0.50, hlt 0.90, wbulbs 0.75, wbul 0.75, hltbs 0.50, hlt 0.50, hltbs 0.75, hlt 0.75, gausbs 0.50, gaus 0.50
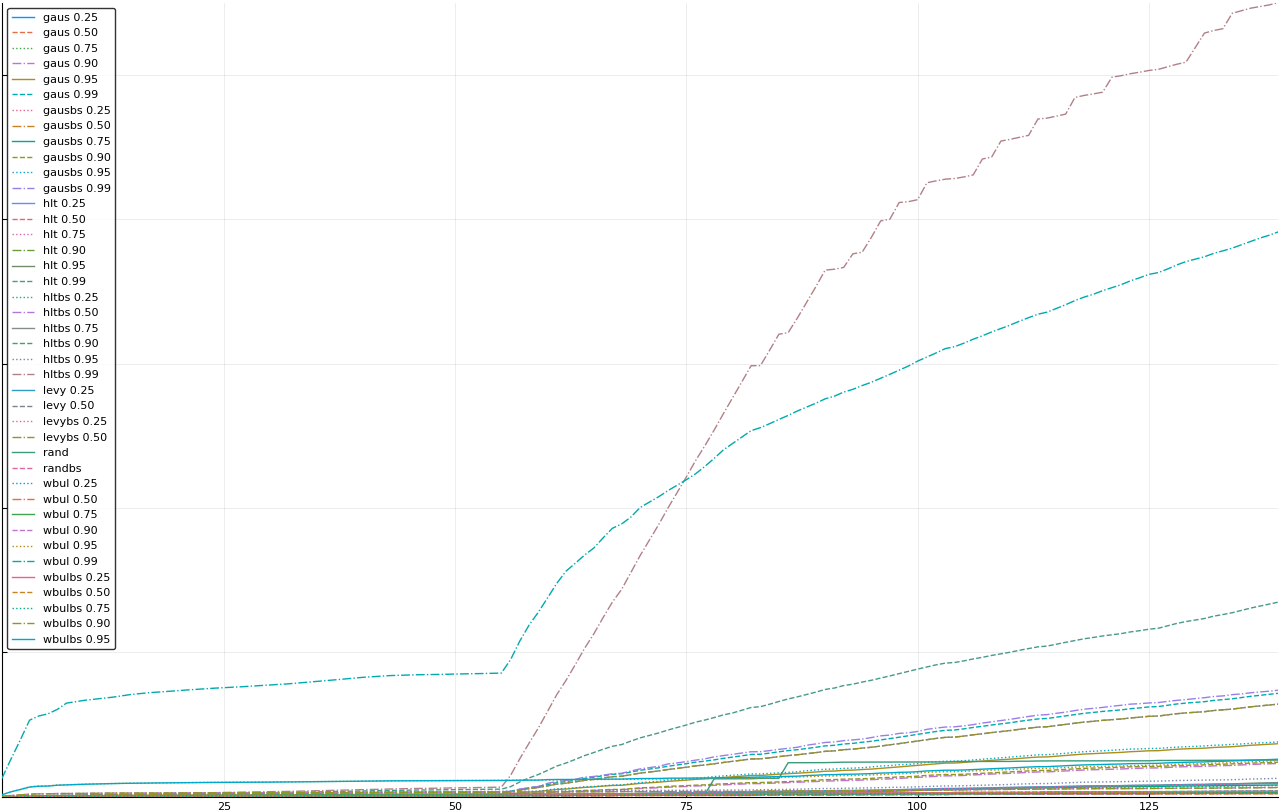
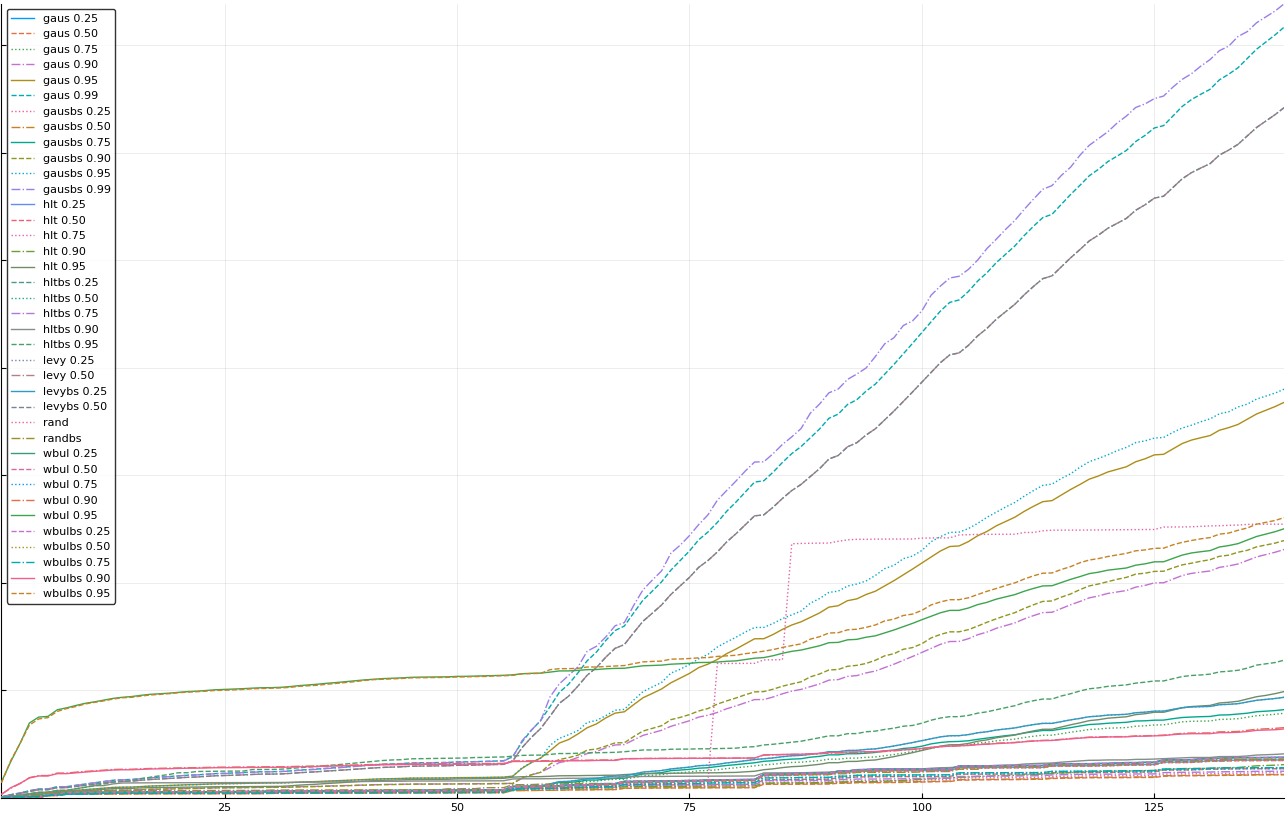
The vertical axis is the accumulated square error with units and values omitted as relative comparison is sufficient. The horizontal axis is enumerating estimates from first to last. Note that the same line style and line color does not represent the same model+percentile from plot to plot. Refer to the legend for identification of model and percentile.
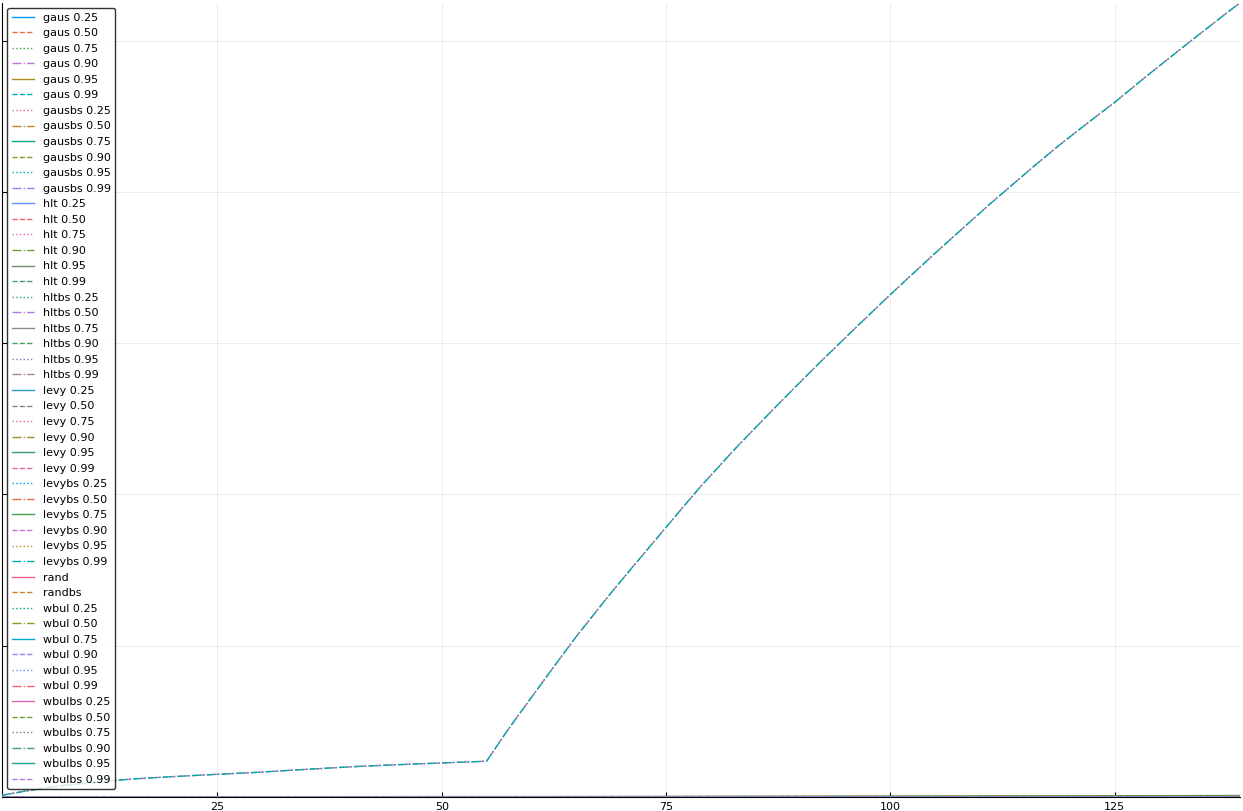
All models and percentiles
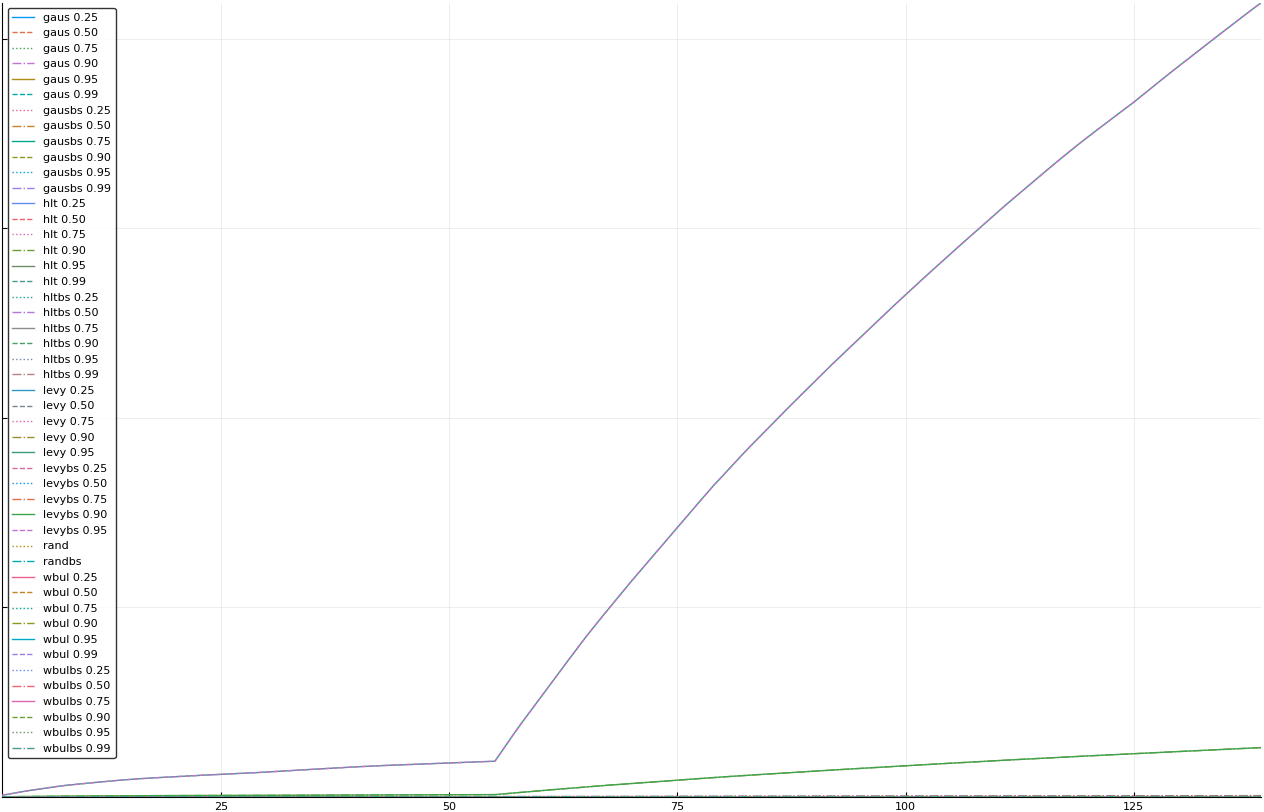
Eliminated levy 0.99 and levybs 0.99

Eliminated levy 0.95 and levybs 0.95

Eliminated levy 0.90 and levybs 0.90
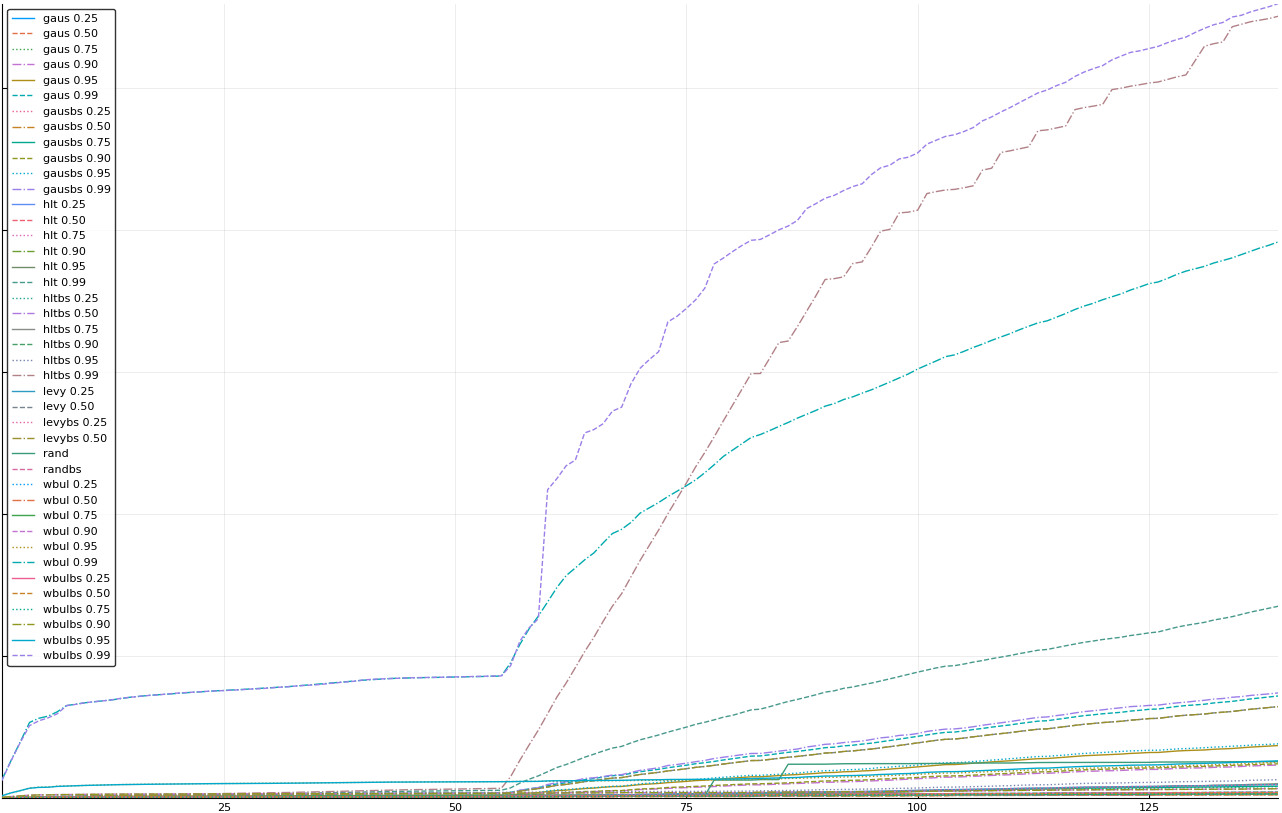
Eliminated levy 0.75 and levybs 0.75
Eliminated wbulbs 0.99

Eliminated hltbs 0.99

Eliminated wbul 0.99
Eliminated hlt 0.99
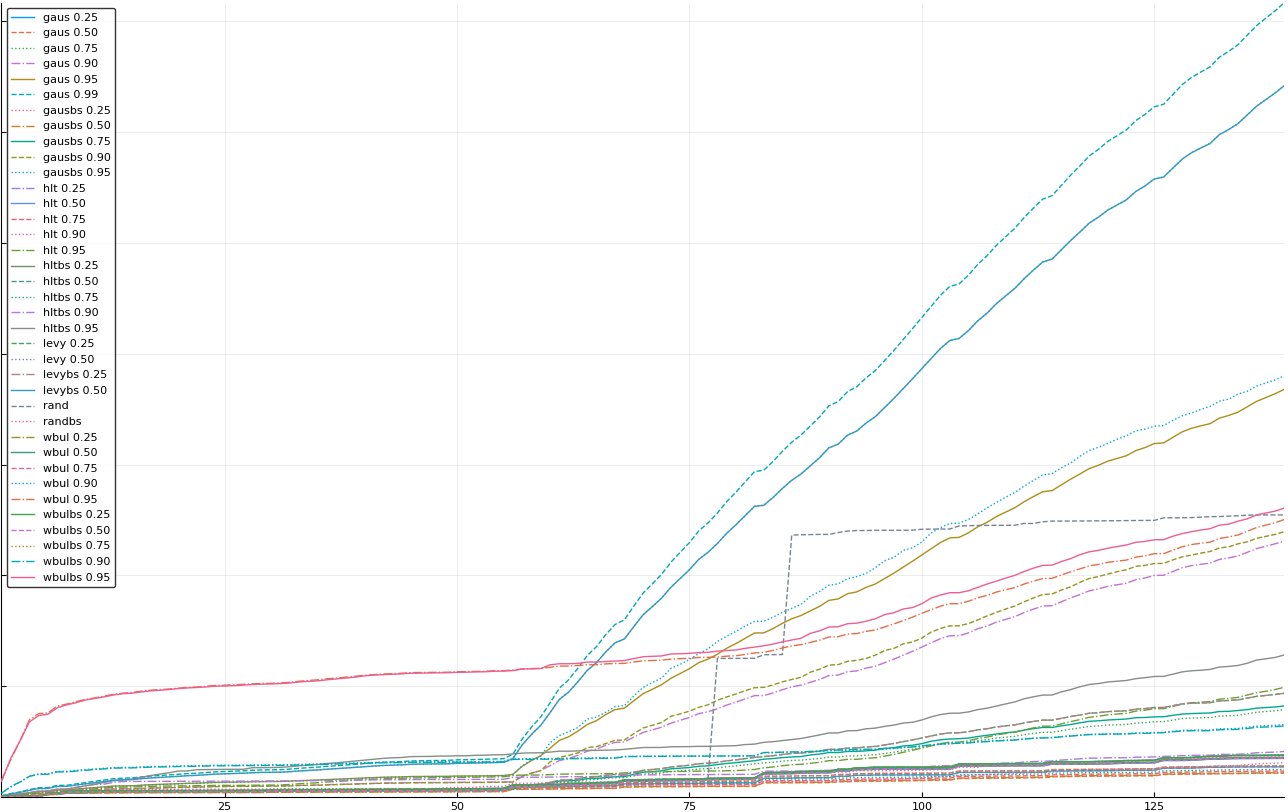
Eliminated gausbs 0.99

Eliminated levy 0.50 and levybs 0.50
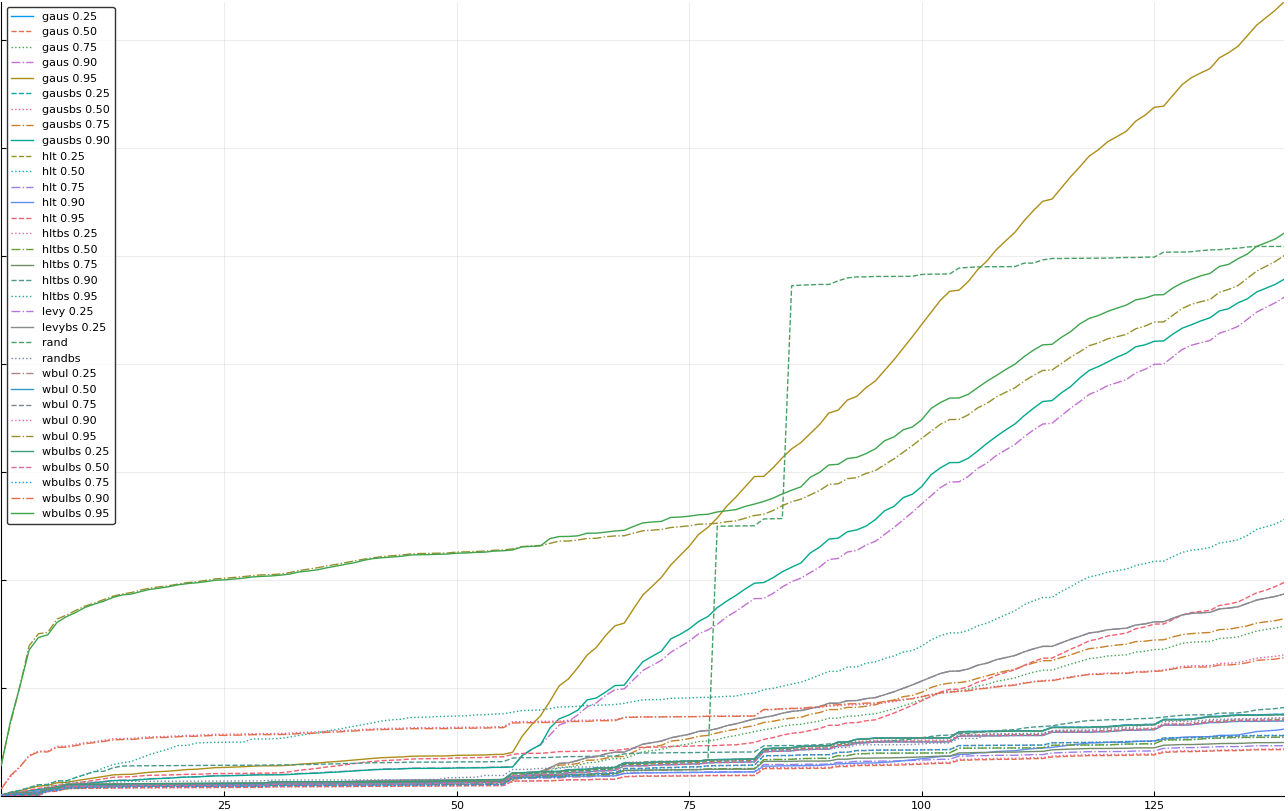
Eliminated gausbs 0.95

Eliminated gaus 0.95

Eliminated wbulbs 0.95
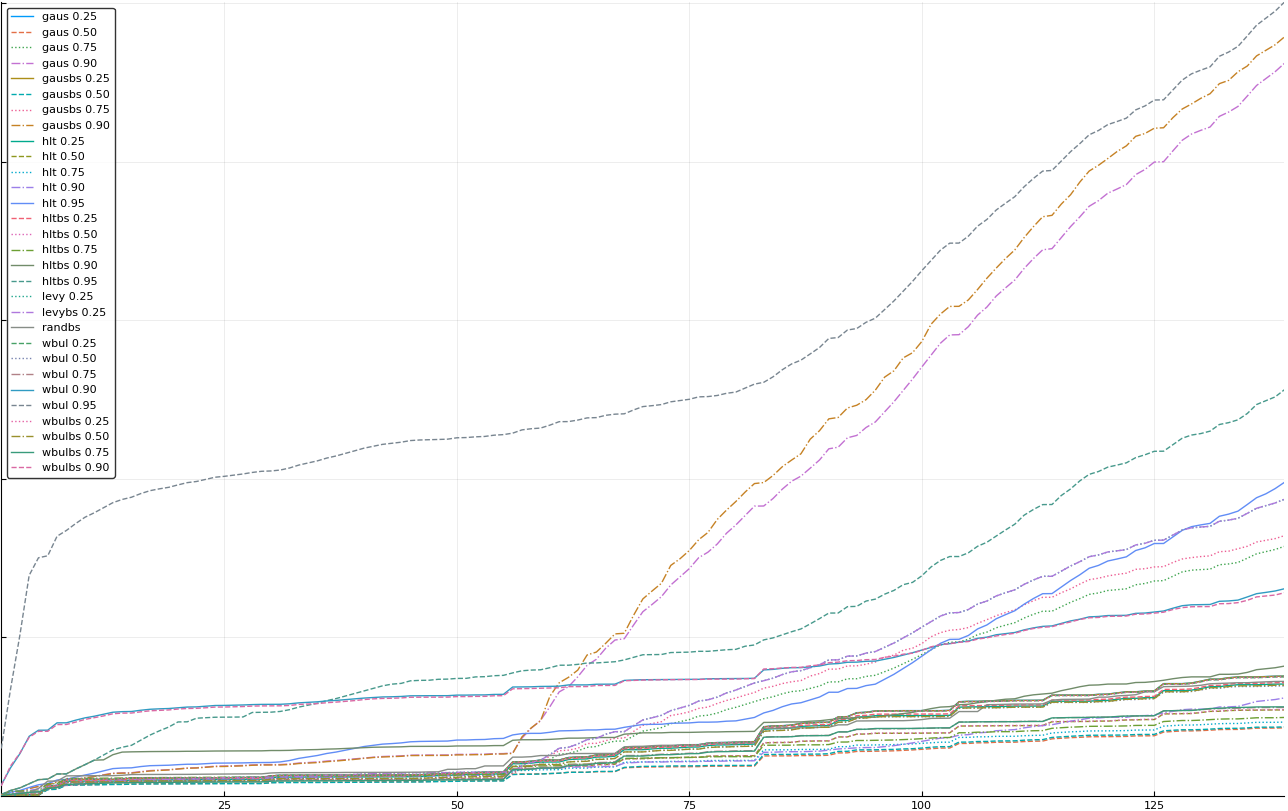
Eliminated rand (displayed are all experiments that performed better than rand)
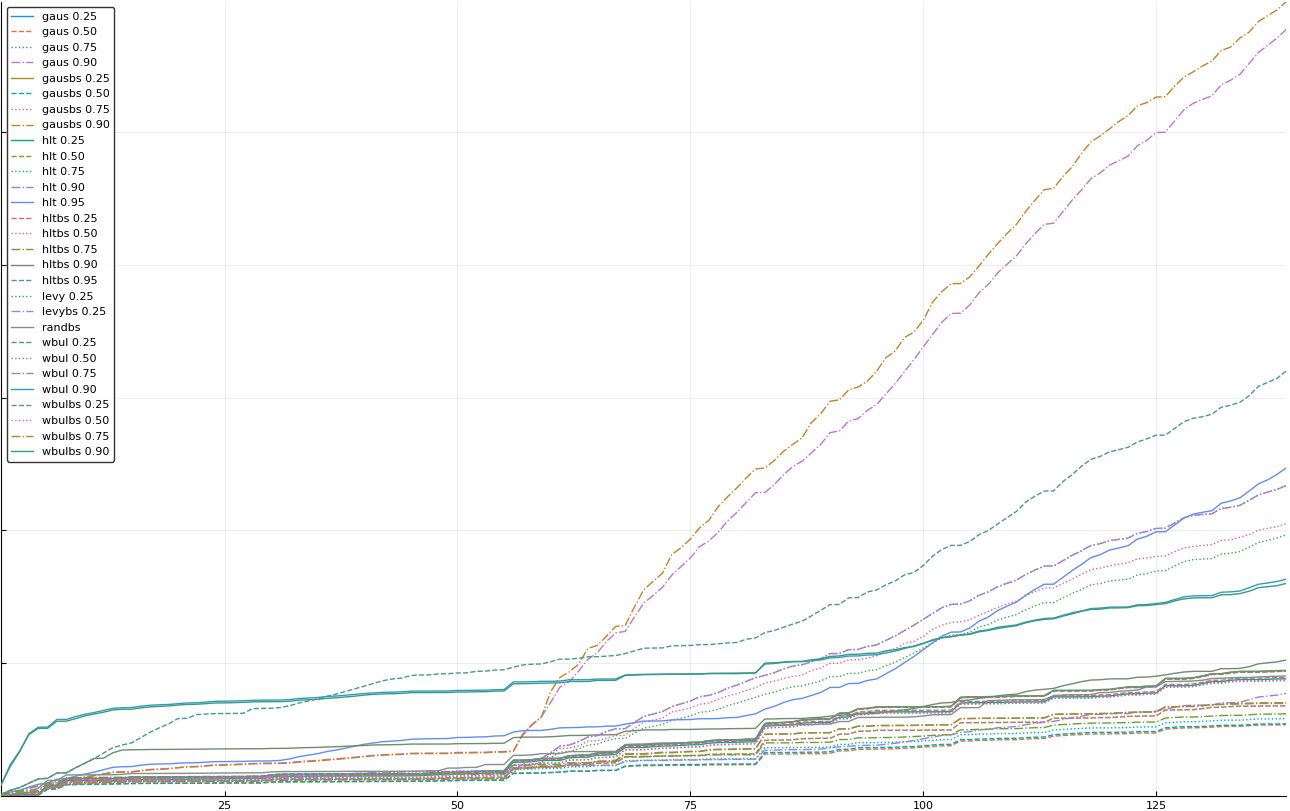
Eliminated wbul 0.95

Eliminated gausbs 0.90
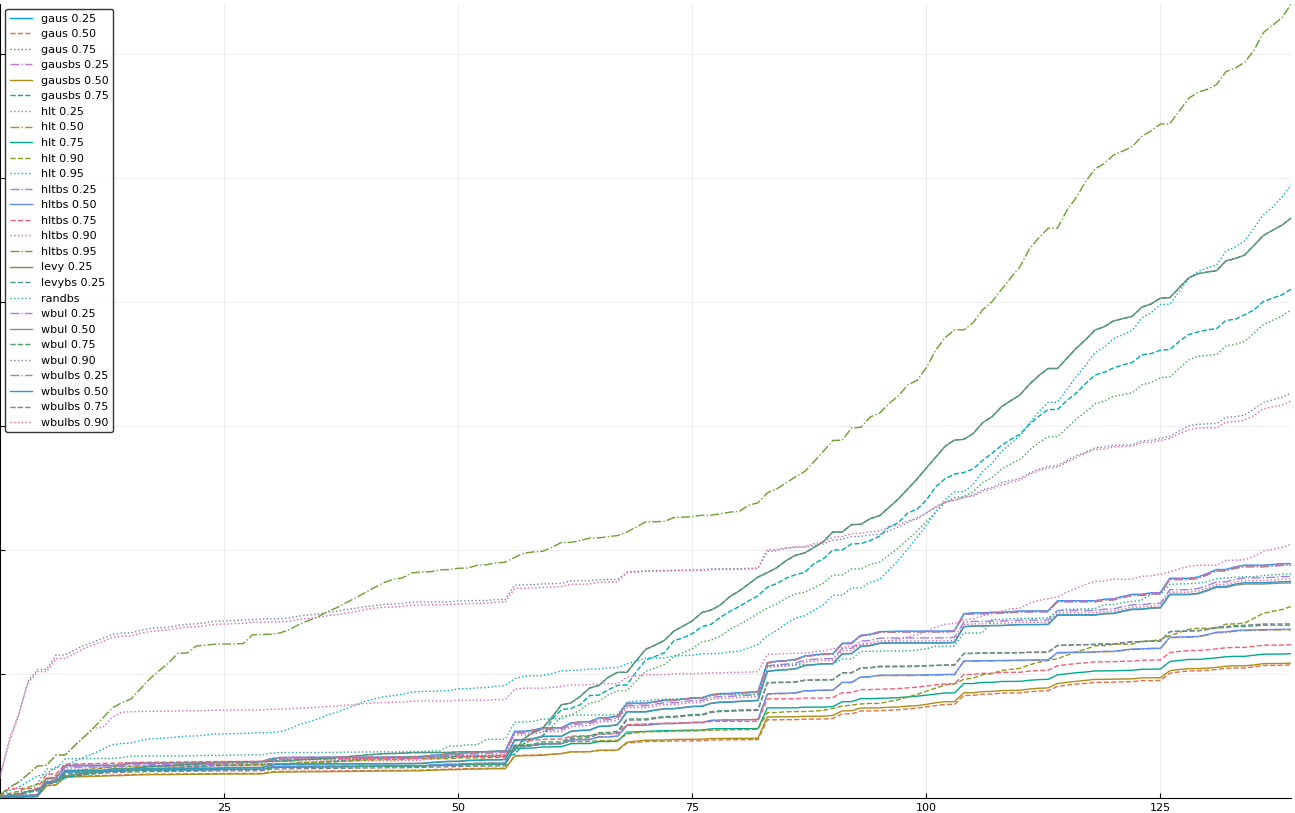
Eliminated gaus 0.90

Eliminated hltbs 0.95

Eliminated hlt 0.95

Eliminated levy 0.25

Eliminated levybs 0.25

Eliminated gausbs 0.75

Eliminated gaus 0.75

Eliminated wbul 0.90

Eliminated wbulbs 0.90
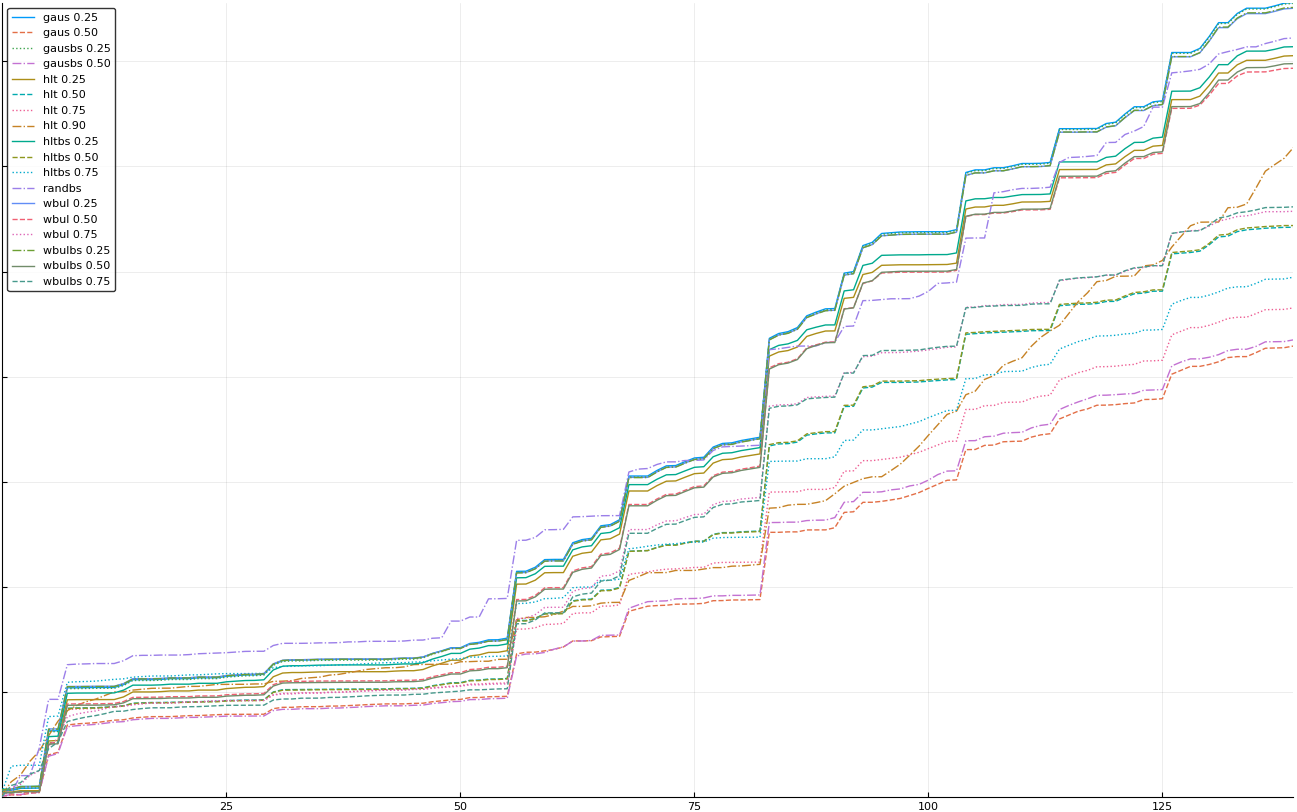
Eliminated hltbs 0.90

Eliminated gaus 0.25

Eliminated gausbs 0.25

Eliminated wbulbs 0.25
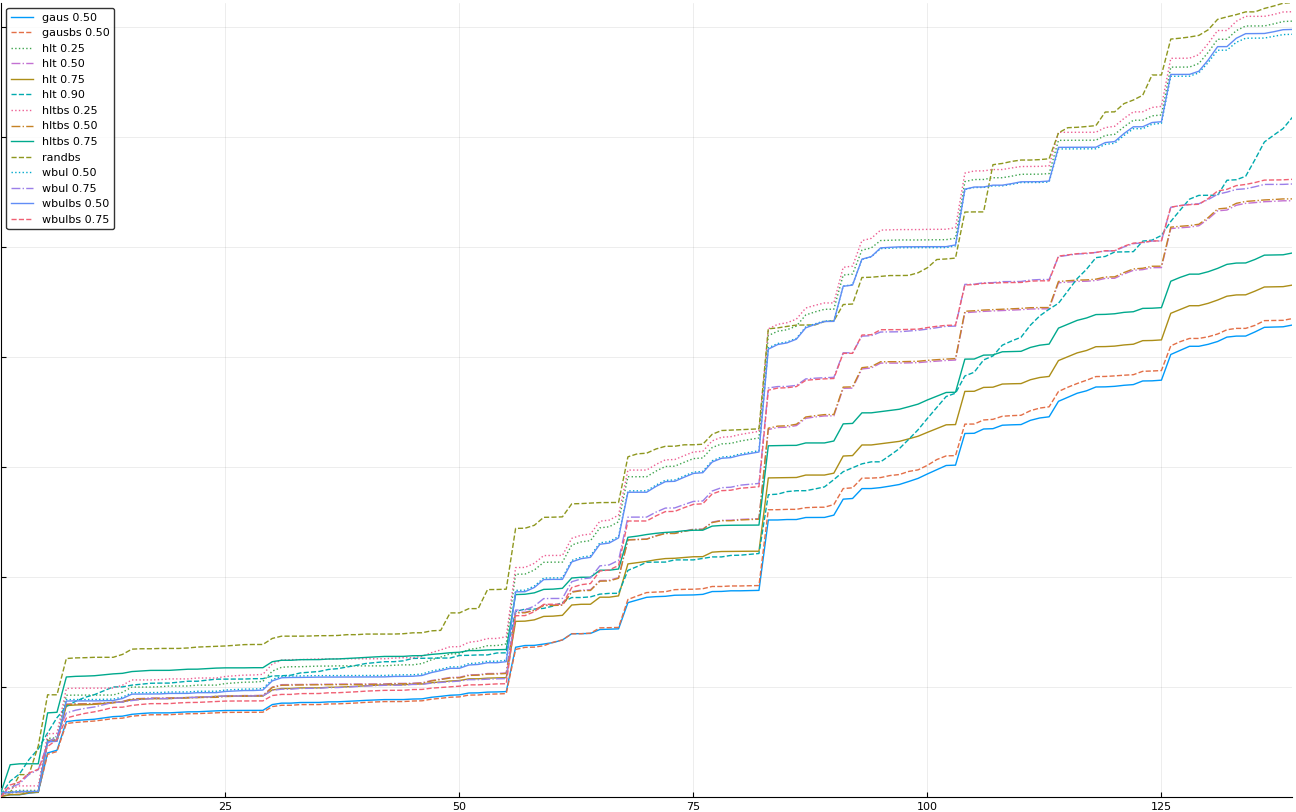
Eliminated wbul 0.25

Eliminated randbs (displayed are all experiments that performed better than randbs)
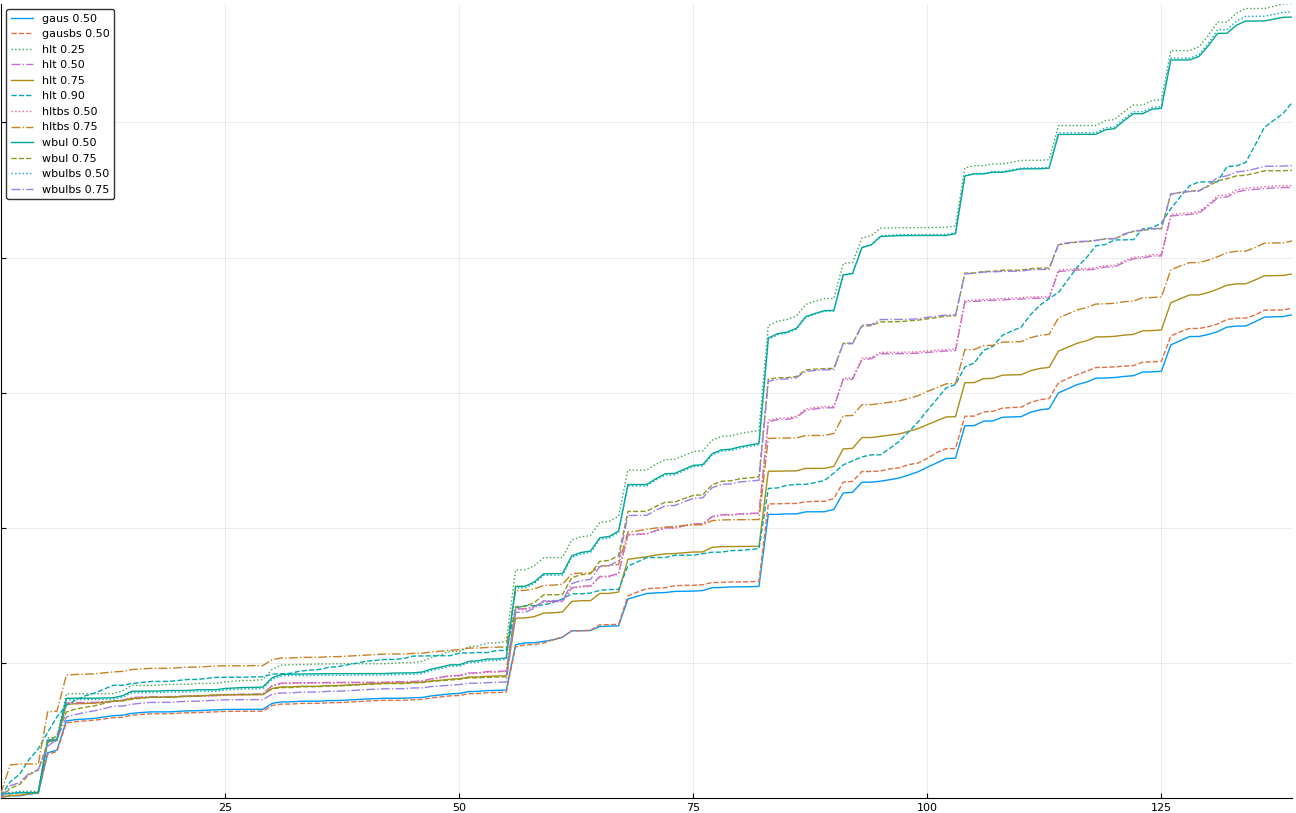
Eliminated hltbs 0.25
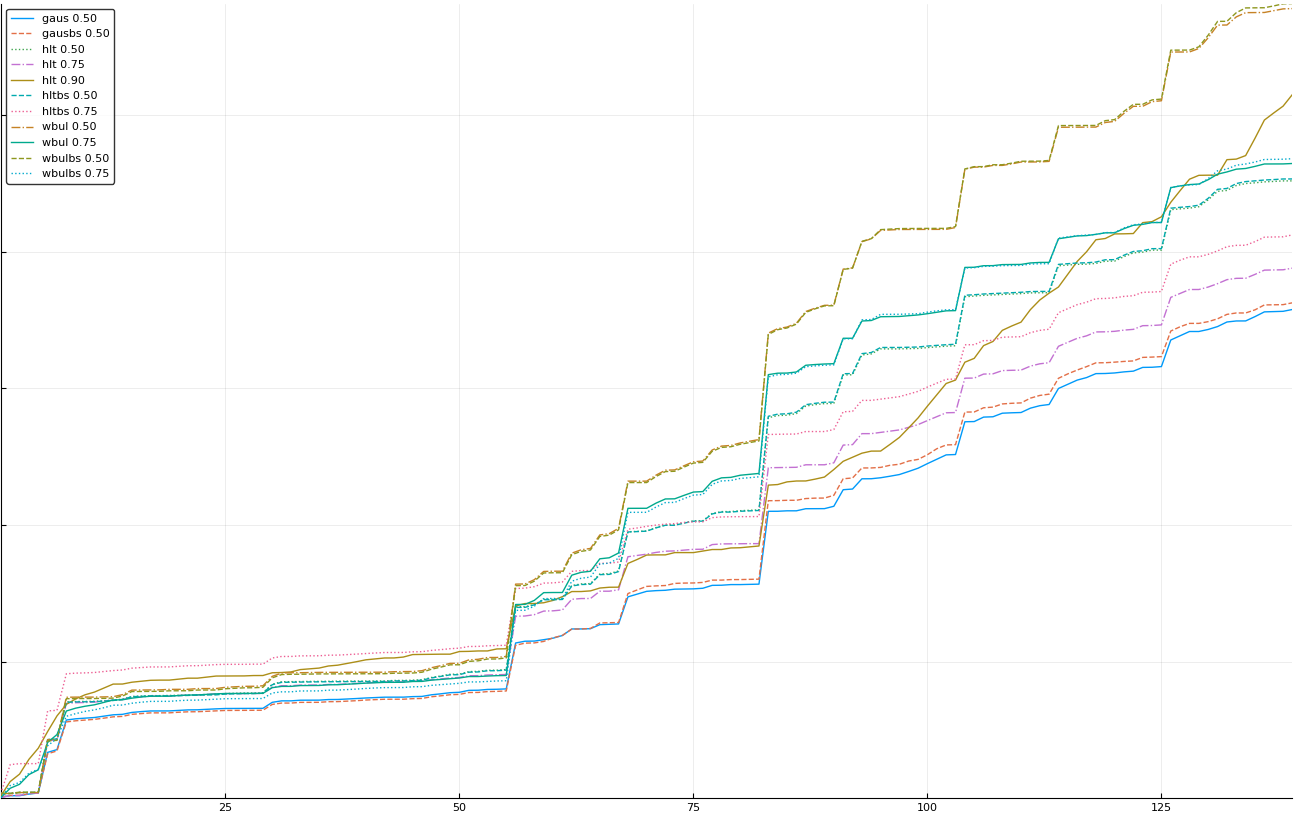
Eliminated hlt 0.25
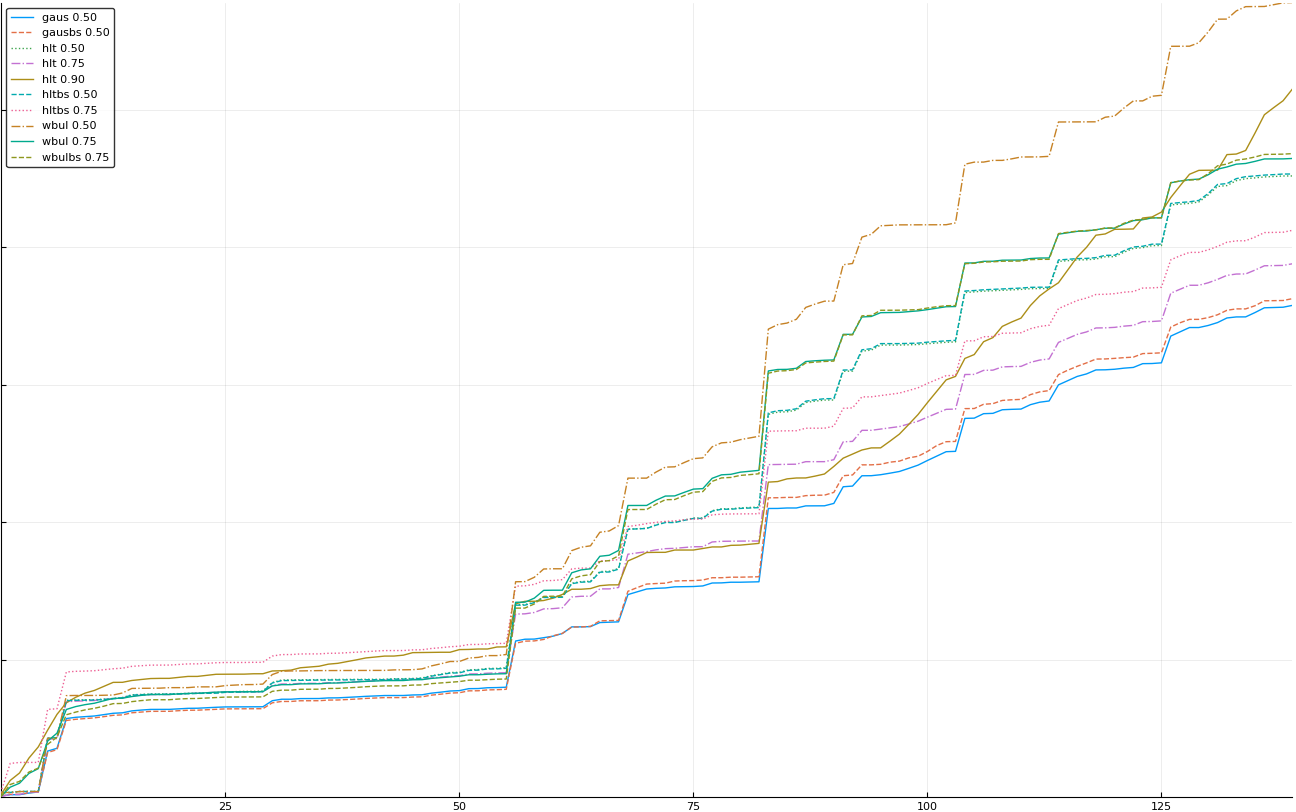
Eliminated wbulbs 0.50

Eliminated wbul 0.50
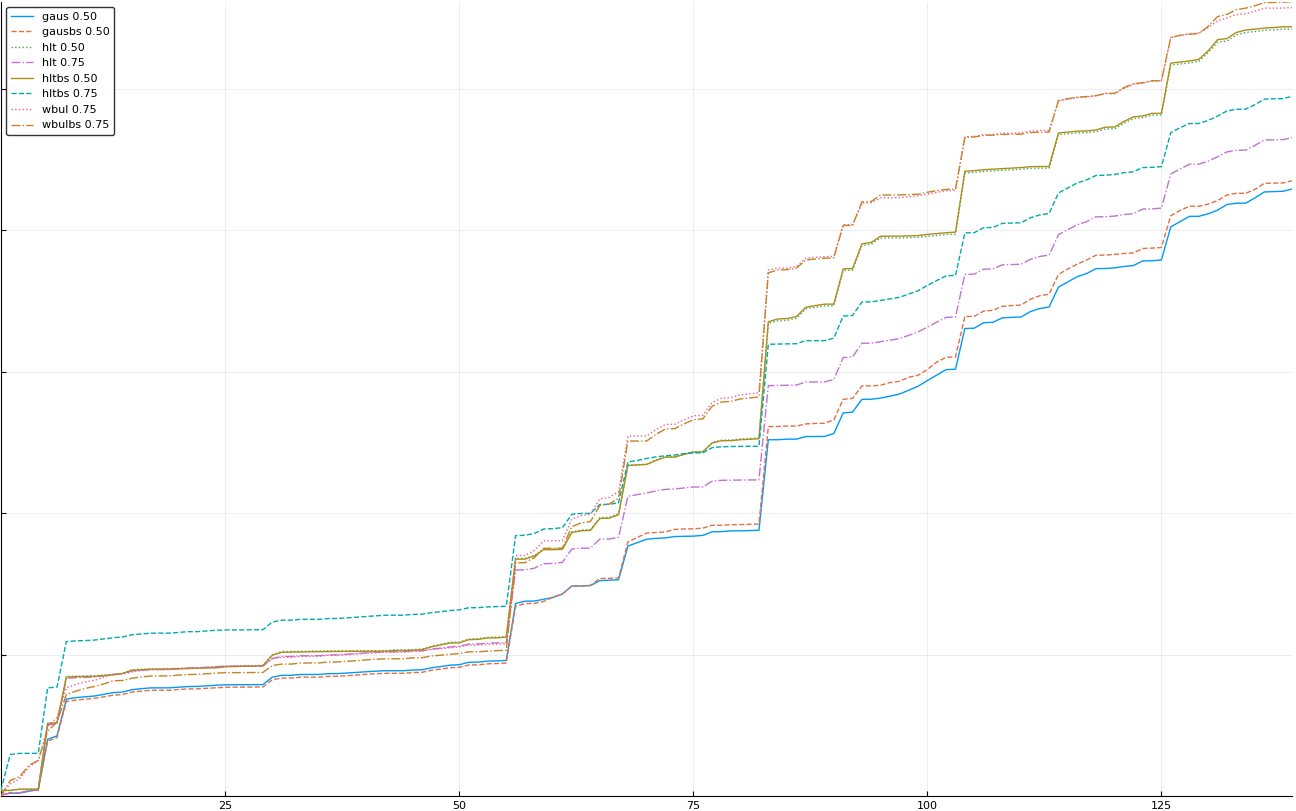
Eliminated hlt 0.90

Eliminated wbulbs 0.75

Eliminated wbul 0.75

Eliminated hltbs 0.50 and hlt 0.50
Experiment Analysis
Main concern is that experimental data is only one data set of 150 items. While the results are surprising, they may not be typical. I need other data sets to run this experiment on (please get in touch if you’re interested in testing your data set).
Regarding accuracy, the fitting of Levy distribution was fairly unsophisticated (calculate mean and variance of sample and use that to generate a Levy distribution). I didn’t expect Levy to perform well and as it was just background to testing the main hypothesis, I didn’t bother implementing a more sophisticated distribution fitting. Weibull distribution, on the other hand, is a pretty good fit as it uses least-squares fit to observed distribution. In summary, Levy distribution fit is crap, Weibull distribution fit should be pretty good. Gaussian distribution fit is straightforward, so it should also be good.
It is interesting to see the impact of outliers on estimation method (large spikes in error graphs). While an outlier destroys some estimators (one can observe points in the graphs where estimator makes a turn for the worse and rapidly departs from best performer), other estimators seem to be robust to outliers. Note that model may be robust or not depending on which percentile is used for estimation.
Another thing of note is that the best performing percentiles are 50th and 75th and not others. This attraction toward the average was a surprise.
Why does “pick the average so far” (more precisely, pick 50th percentile of estimated normal distribution from observed data without bootstrapping) work so well? I assume that part of it is due to normal distribution being robust to outliers, especially once there is enough data to anchor the distribution away from the outlier pretty well. I’m not sure why HLT 75th percentile is better than HLT 50th though.
Bootstrapped random estimator (rndmbs) performed really well, and it also has the same shape as the winning estimators. Note that rndmbs used the same random seed as rndm to select a number between zero and maximum in the sample. What most likely happened is the interplay between bootstrapping process (sampling with replacement) and random estimate being a random number between zero and maximum in the sample. Early on, before the outlier, bootstrapping did not change the maximum, and random estimators chose the same number up to the same maximum. Once an outlier occurred, we see that rndm selected it at least twice. However, it may be the case that the bootstrapping process for rndmbs did not pick the outlier into the bootstrapped sample, allowing rndmbs to pick from a smaller numeric range. From the plot of rndm, it looks like rndmbs only had to get lucky like this twice.
Experiment Learnings
It seems that in order to minimize error in estimates, the best thing to do is pick an estimator robust to outliers. In particular, the best (according to this data set), is to estimate a normal distribution from observed data and pick the mean. If this holds for other data sets, it means that we can all let go fancy statistical methods and use this very simple “pick the average” approach from now on. Imagine how much simpler our estimating lives could be ;).
Questions For The Future
Do these patterns hold for other data sets? If you have a data set, please get in touch.
The experiment only checks the estimation at the start of work (typically when we do estimation), but this doesn’t take into account the full HLT technique of continuous estimation. How good would these estimators be in a continuous (for example, once a day) estimation?
The experiment does not check if models get better at estimation as time progresses. This may be interesting to see.
Typically, when we estimate, the impact of finishing early and finishing late is asymmetric. What would be the results under different penalties for having estimates that are too optimistic (work actually takes longer than estimate).
What is the impact of choosing different seeds for bootstrapping as well as different seeds for estimators using random?
Things I Learned Riding The 2017 Tour Divide

This summer, I rode my bicycle from Banff, Alberta, Canada to Antelope Wells, New Mexico, U.S. It ended up being 2783.6 miles, 165,700 feet of elevation gain, and it took 36 days 4 hours 51 minutes.

Here’s what it felt like…
VIDEO UPDATE: It goes silent at 6:58 due to copyright takedown. Play https://www.youtube.com/watch?v=Rnc1e… as the soundtrack in another tab when you get there.
Here’s what I learned (in no particular order)…
Horizons are closer than they appear
I kept making the same mistake over and over again, and that is, underestimating my ability to cover ground on a bicycle. I can recall numerous times when I looked from elevation onto the terrain around me, towards the horizon which my route would take me over, and think to myself that it’ll take me the rest of the day to get there. Many times, an hour or two later, I would be standing at that horizon looking at another one. There’s a metaphor in there somewhere, but I leave that up to you. What I remember is that horizons are closer than they appear.
Human civilization’s systemic layout
I’m not much of a camper. In fact, I only camped three times on the entire journey. The rest was spent in some sort of lodging accommodations, often accompanied by food resupply. While moving across the country, I kept particular attention to available water sources, since running out of water between water sources is not something I was interested in. I had a nice set of maps to work with throughout the route, so I wasn’t riding blind or anything. Nevertheless, this constant focus on supplies, after a while, gave me a weird sort of intuition about the layout of human civilization around me. I still struggle for words to describe what it feels like. It was a sort of awareness of where I was in the world. I had a constant awareness of, if something goes wrong, what recovery route to take, where is water, where are roads, where is next human settlement. A lot of my trip was going from one human settlement to another. This made me very aware that without those settlements, I wouldn’t last long. I certainly wouldn’t be able to cover ground as quickly as I did, repairing my bike when it broke down, or resting when I got tired. This awareness expanded, over time, to the things I encountered. I spent a lot of time riding on logging roads, so my brain learned “that’s where wood comes from.” I spent a lot of time riding through natural gas fields, mines (the ones where people dig into the ground for resources, not the exploding ones), even past a uranium mill. My brain learned “this is where energy comes from”. And always… cows and fields, everywhere. “This is where food comes from.” If you already have this awareness, none of this is illuminating, but, growing up in a city, I had a mental model for all this, but never felt it viscerally in my body. Being immersed in it, for as long as I was, on my tiny human scale, gave me an inner awareness of it all. For instance, I learned what services to expect at a specific settlement size, depending on what type of road it was on. There is definitely some sort of structure to human layout on the Earth. I got a glimpse of it to some extent.
What the fuck do I (and you) know?
Seeing this much of the country and interacting with all sorts of people… well, people that look like me most of the time (>__> )… anyway, regardless… all sorts of people (even within the sample I came across), really put in check my ideas about how things ought to be. That person in Montana, who lives there, hunts stuff, and lives their life thereabouts, seeing a glimpse of how they live their life, gave me a pretty good indicator that I have no clue how they live their life. Vice versa, they have no clue how I live mine here in Austin, TX. This was a humbling reminder. Also… everyone is super nice one-on-one.
Everyone is on their own epic journey
I noticed that everyone wanted to help me and make sure I was OK. Seriously, riding on a bicycle, obviously dressed like a long-distance traveller, really brings out the Samaritan in everyone. Additionally, seeing other travelers on the trail doing the same thing I was doing, going either the same direction or opposite, made me want to help them because it was obvious they were on an epic journey and I wanted them to be OK. At some point, I was able to make a mental leap that everyone of us is on an epic journey, except that we’re dressed normally, and our goals and constraints are much more complicated than riding a bicycle from point A to point B. Experiencing the journey gave me a tool to reach for in order to try to be better about helping other people. I just imagine them on a bicycle, covered in mud, riding somewhere along the route.
Tour Divide is one of the easiest things I’ve done, psychologically
To be clear, I trained for the journey, and I was in pretty good shape when I started training. But, what I’m talking about is the contrast of what my mind goes through when riding the Tour Divide, versus, living in the world. All I had to do was plan the next day, execute the plan (ride), made sure I was hydrated, feed myself, find shelter, and repeat, until done. Most of the time, the sole thought on my mind was “keep pedaling.” Mentally, it is simpler than pretty much any interaction I have now that I’m back in civilization. Navigating complexity of our modern human society is much more difficult and less satisfying. After some discussions about this particular learning, I did stumble upon a model that might possibly explain why this is the case.
Consider Daniel Pink’s “Autonomy, Mastery, Purpose” model for intrinsic human motivation along with Abraham Maslow’s Hierarchy of Needs model that progresses from most basic human needs to most complex: Physiological, Safety, Social Belonging, Esteem, Self-Actualization. When I was riding the bike, the needs I had to maintain were Physiological and Safety, i.e. don’t get hurt, don’t die, make it to next shelter. Achieving Autonomy, Mastery, and Purpose is rather straightforward for those needs (given proper preparation and supplies). I was at the height of happiness squatting by a mountain stream, filtering my water, and pumping it into my Camelback. That’s all it took for me to feel “I’m the boss of this! I can survive!”. In the evenings, however, once I found shelter and my Physiological and Safety needs were met, my brain started reaching for Social Belonging. Achieving Autonomy, Mastery, and Purpose in Social Belonging is difficult to do by yourself, and so the nights felt lonely in my shelter. Now, that I’m back in civilization, I’m working on Self-Actualization… that is orders of magnitude more difficult than lower sets of needs in the hierarchy. So, less happiness, less often for me.
Average knowledge vs. peak knowledge
Once I got into few days of the ride, I started imagining what would be something “extreme” for a person to do. “What if,” I thought, “I would ride down to New Mexico, and then turn around and ride back to Canada!”. That would be XTREME! Well, that’s because I was unfamiliar with what I was doing, I only had some average knowledge of Tour Divide and its possibilities. Turns out, that when I was riding, there was a person who was doing a double yo-yo. A yo-yo is starting at one end, going to the finish, then turning around and finishing where you started. This person was doing that twice. Another person, in a previous ride, started their ride from Costa Rica, so that by the time they made it to New Mexico, they’d be “in shape” to do well riding the route northbound.
It turns out that the most “extreme” thing I can imagine about something I’m unfamiliar with, is not extreme enough. If I have only average knowledge of something, I can’t imagine the possibilities. I can only imagine an average extreme. People, for whom this is their niche, do much much much more extreme things. They have peak knowledge of their niche, and it turns out that I can’t conceive of what the real peak extreme could be.
Honey Buns
Honey Buns turned out to be my main source of calories. They turned out to be the appropriate combination of calorie density per volume, not melting, as well as not requiring any external water to consume. There were days where all I ate was a Honey Bun per hour.
Colorado smells like weed
Yup. Pretty much that’s what I remember about Colorado. The woods smell like weed.
How Long Will It Take?
Estimating Software Work
Like many people who find themselves doing software development, I am sometimes asked to estimate when work will be completed. What I’m going to demonstrate is the best way I know of estimating software work completion. Next time someone asks “how long will it take?”, in the time it takes you to read this sentence, you’ll be able to answer with things like “when starting new work, there’s a 25% chance it will take us less than 3 days, 75% chance it will take us less than 37 days, and 90% chance it will take us less than 104 days” and be able to provide any other percentile you want.
First, a constraint I want in place is that people should not have to make any guesses about the nature of the work or the difficulty of the work in order to generate a reasonable estimate. This constraint is in place because in the value stream mapping sense, estimation is waste. Therefore, people not doing estimating eliminates the estimation waste.
Next, let’s go over the assumptions I’m going to make about the work. For the purpose of estimation:
Work is some problem to be solved. When the problem is solved, the work is completed.
Work is in the domain of software development. This is where my experience lies, this is the domain I’ve been asked to estimate.
The nature of the work does not matter. It can be a typo in information being displayed, or it can be a customer-facing availability outage for unknown reasons.
We do not know the probability distribution of the work. This last assumption will take some explaining.
Imagine that you have a record of the work you’ve completed over some period of time in the past, for example over the past two years you’ve completed 150 work items. For each work item (a solved problem), you have a start date and an end date. These give you a duration of the work, or how long a work item took to complete. So, in our example, you would have a list of 150 durations. If you were to create a histogram of work duration, you would see a duration distribution of the work. The assumption that “we do not know the probability distribution of the work” means that we do not know what duration distribution of the work will look like ahead of time. We might be able to determine the distribution only in hindsight. But, estimation does not happen in hindsight, therefore, at the time we have to make estimates we do not know the probability distribution of the work.
In case you think that work is normally distributed (as in, the typical bell curve that is easy to do statistics with), here is a histogram of 150 actual durations:
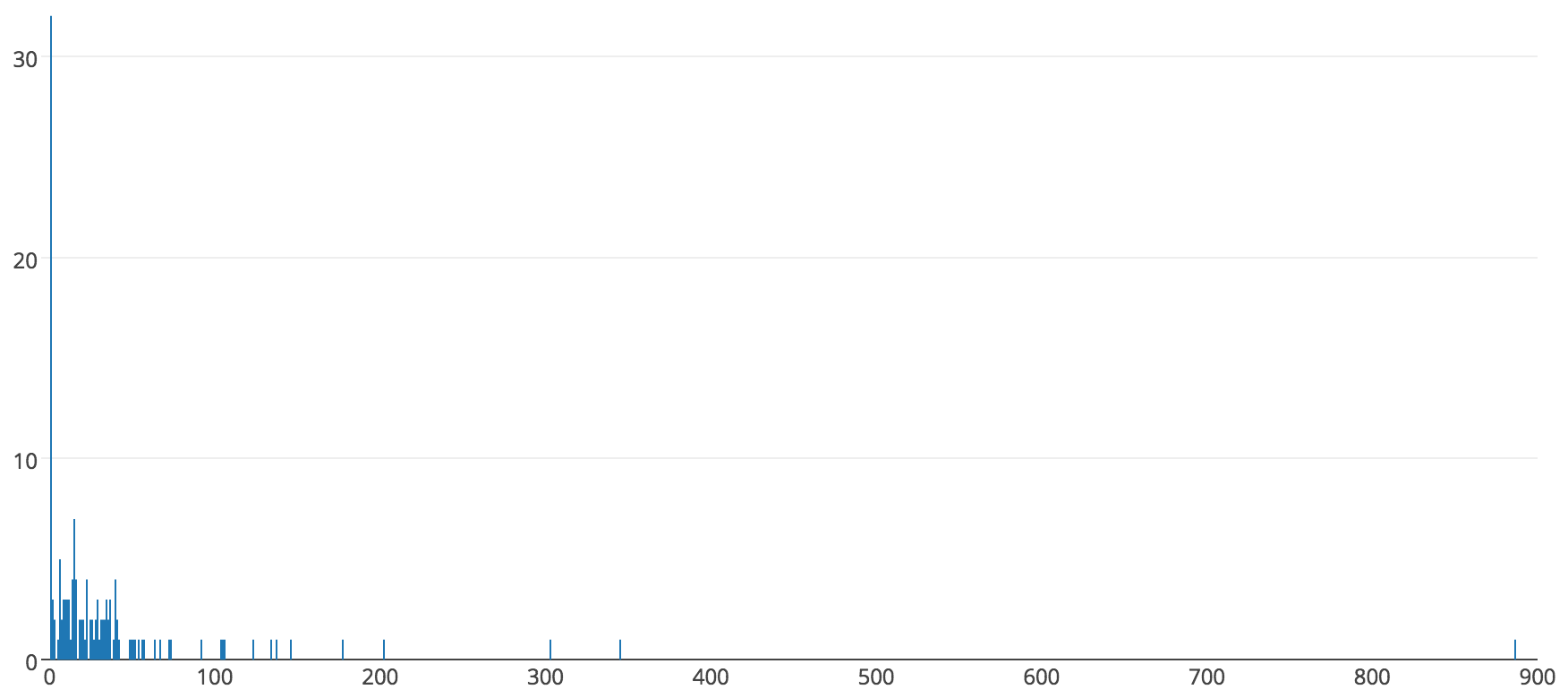
Created using: https://plot.ly/create/histogram/
Now, 150 data points does not a large sample make. So, we’ll need to make another assumption.
Previously observed work durations are representative of the probability distribution of the work. That is, we assume that our past data comes from the same probability distribution of work that our future data will come from1.
If our past data is representative of the probability distribution of future data, we can go through a process of bootstrapping, and generate a much larger data set than 150. We do this by random sampling with replacement of our 150 point data set, to generate, say 1,000 point data set. Basically, we randomly pick one of the 150 points, add it to our 1,000 point data set (which now has one point in it), and put it back into the 150 point data set. We then randomly pick another one of the 150 points, add it to our 1,000 point data set (which now has two points in it), and put it back into the 150 point data set. We repeat until we sampled 1,000 points from the 150 points. What this gives us is an estimate of the “true” probability distribution of the work, given our previous assumptions.
With the resultant 1,000 points, we now sort them from shortest to longest duration. The 90th percentile answer for “how long will it take?” is the 90th percentile of the sorted 1,000 points, in our example, it turns out to be 103.73125 days, or under 104 days. That’s it. If you automate this, you’ll be able to rapidly provide any estimate of work completion to whatever percentile you’d like2.
One more thing…
There is an interesting, and I believe important, question to consider aside from “how long will it take?”. That is, “how long will it take to finish work you already have in progress?”. The answer is surprising (at least it was to me the first time I saw what happens). Let’s go through an example.
In this example, I will just use ten data points as our entire sample to illustrate what happens. Here they are, duration of completed work in days:
0.5, 0.5, 0.75, 1.0, 1.5, 3, 5, 7, 10, 21.5
Given the above historical data, consider now that you are about to start the next work item. In other words, all we know about the work item is that we haven’t started it yet. Therefore, we use all of our ten example data points to bootstrap a larger data set with 1,000 data points, and once we have that, we sort it, and then pick, for example, the 90th percentile. Nothing different from what we’ve already demonstrated.
However, now imagine that it is two days later, and we are still working on our work item. How would we answer the question of how long it will take us to finish? There is a key difference after two days of work, and that is that we have learned that our work item takes at least two days of work. When, after two days of work, we ask the question how long it will take us to finish, what we are really asking is “how long will it take to finish a work item that takes at least two days to finish?”. To answer this question, it makes no sense to use any data points that are less than two days in duration. Data points less than two days in duration clearly do not represent the type of work we are attempting to estimate completion of. If the work was of the type that takes less than two days to do, it would be finished already. So, without data points of less than two days, our data points to bootstrap from are now:
3, 5, 7, 10, 21.5
If you bootstrap from these data points, something interesting happens, and that is, that the 90th percentile will now very likely be further in the future than the estimate you gave when you asked the question two days prior. So, on day 0, when you haven’t started work, you used all data points, and the 90th percentile could end up being 10 days to finish. On day 2, when you worked for two days, using the newly learned information, we update our starting data set, and the 90th percentile could end up being 21.5 days to finish.
In fact, if you’re working on a work item, and every day you ask “how long will it take to finish?” the answer tends to be further and further in the future3.
Here is an example of the 90th percentile estimate for work item duration if we ask the question for the first thirty days, and the work item is not finished:
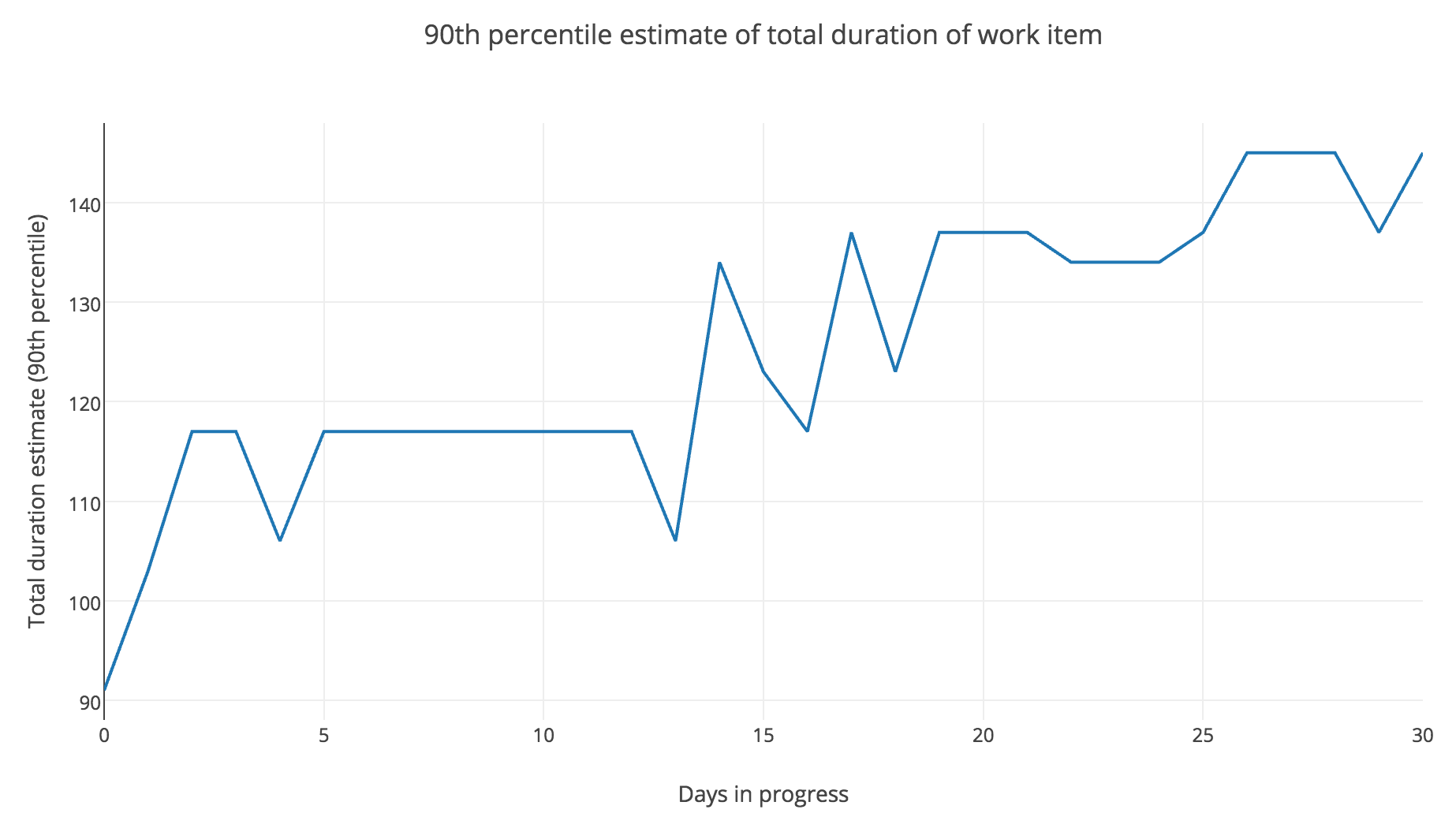
Created using: https://plot.ly/create
Wait, what?!
What I presented here is, I think, a reasonable methodology for estimating work. It works at a level of solving problems, which is what “the business” usually cares about. It makes reasonable assumptions, it gives estimates as percentiles, which is better than a single estimate because we can adjust for our individual risk tolerance. Also, this method generates estimates without involvement of any human (once it is automated).
Then again, because this method is automated, it allows us to ask the question “how long will it take?” as often as we like. What we learn, is that every time we ask, the answer will be further in the future, and we will be more confident of the answer.
The best time to know when something is done, is when it is finished. But if you insist on asking, you might not like the answer.
Endnotes
1 More precisely, I am assuming that the past data comes from the same generator type that our future data will come from. The distinction, while interesting, isn’t important to the overall effort, so I won’t cover it further in this post.
2 To be even more… statistically valid (maybe?), you could regenerate your 1,000 point data set many times and take the average of the percentile you’re interested in across each generation. Then you can say you’re using a Monte Carlo method to derive your estimates.
3 I find this is a rather fascinating manifestation of the Lindy Effect.
Adding a “margin of safety” is not even wrong…
I just came across a blog post A Margin of Safety: How to Thrive in the Age of Uncertainty via the weekly High Scalability post. But, the advice there is wrong in a subtle way.
Basically, the author claims that if only engineers designing levees and flood walls added a “margin of safety” than a tragedy of flooding brought on by Katrina could have been avoided. I didn’t do the research that the author did on this, so I’m leaving that unchallenged. “Margin of safety” is actually a good advice for a specific context. The problem is when the author extrapolates it to how to use “margin of safety” in “real life.”
The author bundles together domains with completely different characteristics and applies the same heuristic as general advice across all of them. This is a mistake. While lifting weights may have properties where adding a margin of safety is reasonable, it is so because the failure mode and the range of lifting weights fits into normal probability distribution of things. You aren’t going to ever squat the weight of the Moon, or you are very unlikely to hurt yourself executing a movement with no weight if you’ve trained that same movement with weights before. The failure domain is for the most part predictable. Investing, on the other hand, is, for the most part, unpredictable, and has no bounds on what is likely and what is unlikely given enough time. No amount of safety margin will prevent you from ruin of the investment you make. Similarly, in the domain of project management itself (also mentioned by the author), there are predictable projects and unpredictable projects. A “margin of safety” will do nothing for you if you’ve attempted the impossible, and, for example, in the software world, it is not always easy to distinguish if what is being attempted is possible or will ever work as intended, especially if it’s novel. And while “margin of safety” sounds great in wildlife management, when there is existential risk involved, sometimes no margin is sufficient to prevent catastrophe.
Closing out along with the author’s closing point, “leave room for the unexpected” only points out that you are leaving room for the unexpected that you expect. There’s the unexpected unexpected (also more commonly referred to as the unknown unknown), which is a property of a complex system. “Margin of safety” doesn’t do much there, being able to react quickly and reinforce or dampen effects is much more important heuristic in such environments because the “margin of safety” is unknown at the time you have to decide what it is.
